在DT(data
technology)时代,网上购物、不雅观看视频、聆听音乐、阅读新闻等各个领域无不充斥着各种保举,个性化保举已经完全融入人们的日常生活傍边。个性化保举按照用户的历史行为数据进行深层兴趣点挖掘,将用户最感兴趣的物品保举给用户,从而做到千人千面,不但满足了用户素质的信息诉求,也最大化了企业的自身利益,所以个性化保举蕴含着无限商机。
号称“保举系统之王”的电子商务网站亚马逊曾宣称,亚马逊有20%~30%的销售来自于保举系统。其最大优势就在于个性化保举系统,该系统让每个用户都能有一个属于本身的在线商店,而且在商店中能招到本身最感兴趣的商品。美国著名视频网站Netflix曾举办保举系统角逐,悬赏 100 万美元,希望能将其保举算法的预测准确度提升10%。美国最大的视频网站YouTube曾做过实验比较个性化保举和热门视频的点击率,结果显示个性化保举的点击率是后者的两倍。
达不雅观数据拥有雄厚的研发保举系统的技术积累,曾在ACM、CIKM、KDD、Hackathon等国际竞赛的获奖,在内容保举,文本挖掘、广告系统等方面申请有超过三十项国家发明专利。本文从数据处理、用户行为建模到个性化保举,分享达不雅观数据在个性化保举系统方面积累的一些经验。(达不雅观数据联合创始人 于敬)
1.数据收集及预处理
保举系统的素质其实就是通过必然的方式将用户和喜欢的物品联系起来。物品和用户自身拥有众多属性信息进行标识。
1)物品属性

用户体现保举系统的主体,自身属性包孕人口统计学信息以及从用户行为数据中挖掘分析得到的偏好等。
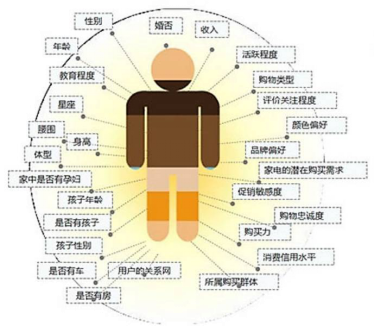
3)用户行为
用户行为分析
在数据采集的过程中,不免会出现一些脏数据,在使用数据前需要进行清洗。过滤掉关键字段为空、数值异常、类型异常等数据;用户id包孕cookie、手机号、email、注册id等,需要进行映射得到用户唯一id;以及数据去重等操作。别的,还有“报答”的脏数据,如作弊、刷单等行为,这些数据也需要清除,不然会严重影响后续算法的效果。达不雅观数据在反作弊方面也做了很多工作,可有效筛选各种行为上的作弊情况。
2.用户行为建模
基于用户历史行为的进行挖掘分析,得到刻画用户素质需求的一组属性集合,即得到用户模型,个性化保举的准确性很大程度上依赖于对用户属性刻画的准确性。达不雅观数据采用了多种方式进行量化,主要包孕显式用户偏好分析和隐式用户兴趣点挖掘。
1)显式用户偏好分析
除了结合物品信息进行分析计算得到的显式偏好外,还有一部分隐式兴趣点需要挖掘,这部分主要用于细分用户群体,进行有针对性的进行更有效的保举。划分群体的准则要按照具体的业务需求而定,好比是否是高价值用户、是否价格敏感、是否对大牌情有独钟、大神用户和小白用户的区分、喜欢热门流行还是偏小众的等等。借助机器学习中的分类(如SVM)和聚类(如k-means)算法可有效解决用户群体的划分问题,牵涉到的训练和测试数据需要先按照一些规则粗略得到候选集,在结合人工标记的进行筛选。除了可以从行为数据中抽取特征外,也可以从物品和用户的属性数据中抽取特征。经过模型的训练、预测和后处理,从而将用户划分到差别的群体。
3)协同过滤的基石
相似度计算方法对保举效果的影响
相似度的计算很多种方法,如余弦相似度、皮尔逊相关度等,曾经使用mahout做过的一个差别相似度度量方法下的对比测试结果,测试中score的计算使用的是绝对差值的平均,越小越好。本次测试结果表白,在基于用户的协同过滤中,使用皮尔逊相关度的计算方法,保举效果最好。
其实差别的相似度计算方法有各自的优缺点,适用差别的应用场景,可以通过对比测试进行拔取。在实际业务中,相似度的计算方法都有很多变种,好比是否考虑去除冷门物品和热门物品的影响。终究过于冷门和过于热门的物品对衡量用户间的相似度时区分度欠好,这时就需要进行剪枝。这种基于K近邻的拔取相似用户的方法,相似度的阈值设置对结果影响很大,太大的话召回物品过多,准确度会有下降。
4)时间维度上的考量

3.个性化保举的实践经验
