GNU/Linux是产品开发和运行的平台。 Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证。
所以首先我们需要下载Linux的ISO安装包安装,具体安装参考我的上一篇博客:
VirtualBox虚拟机以及CentOS系统的安装【详细】
可以去官网下载或者下载我上传的资源,我所用的具体版本如下图所示:

链接: https://pan.baidu.com/s/1XTZfzl0t79Dtz0-jmQrQuQ 提取码: pkwy
主要作用是用Xshell 7进行虚拟机各项操作,用Xftp 7将本地的jdk及hadoop安装包传输到虚拟机上
两个工具均可以在官网下载,选择个人使用方式可以免费下载
需要注意的是在参考上篇博客安装CentOS设置网络连接时两个网关都要打开,具体如下:
启动之前进行网络设置


然后点击启动,进行到下列步骤时注意将两个网关打开并对第二个网络进行手动配置
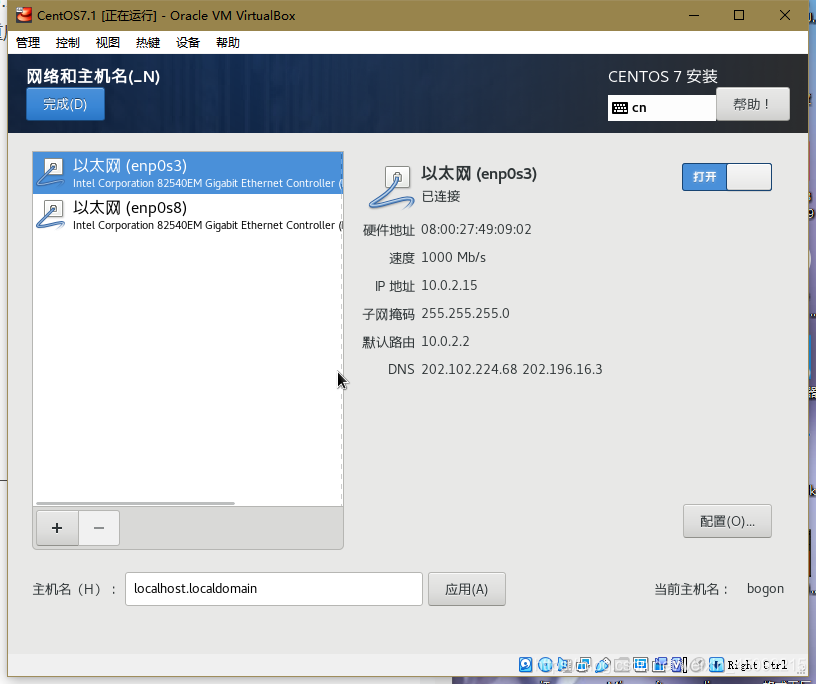

点击配置,手动配置Ipv4,将框内地址填入对用项,点击保存。
Centos安装后,点击启动,在终端登录root账户后,输入ifconfig命令,检查网络配置,如果不存在,执行命令yum install net-tools.x86_64,弹出y/n的话,选择y。

执行
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
把onboot=no改成yes
点击insert键(即键盘i键),上下移动到那里改好之后,按esc建退出编辑模式,然后再按:wq就可以保存退出了,注意有:
不出意外,网络已经配置好了。
重启虚拟机或者重启网卡服务
service network restart
登录后 再次输入ifconfig命令,已经有了反馈信息,如图将框内IP地址记下

打开Xshell,新建连接,将IP地址写入下图框内,即可在本地建立与虚拟机的连接,后续对虚拟机的各项操作均可在Xshell终端中进行。

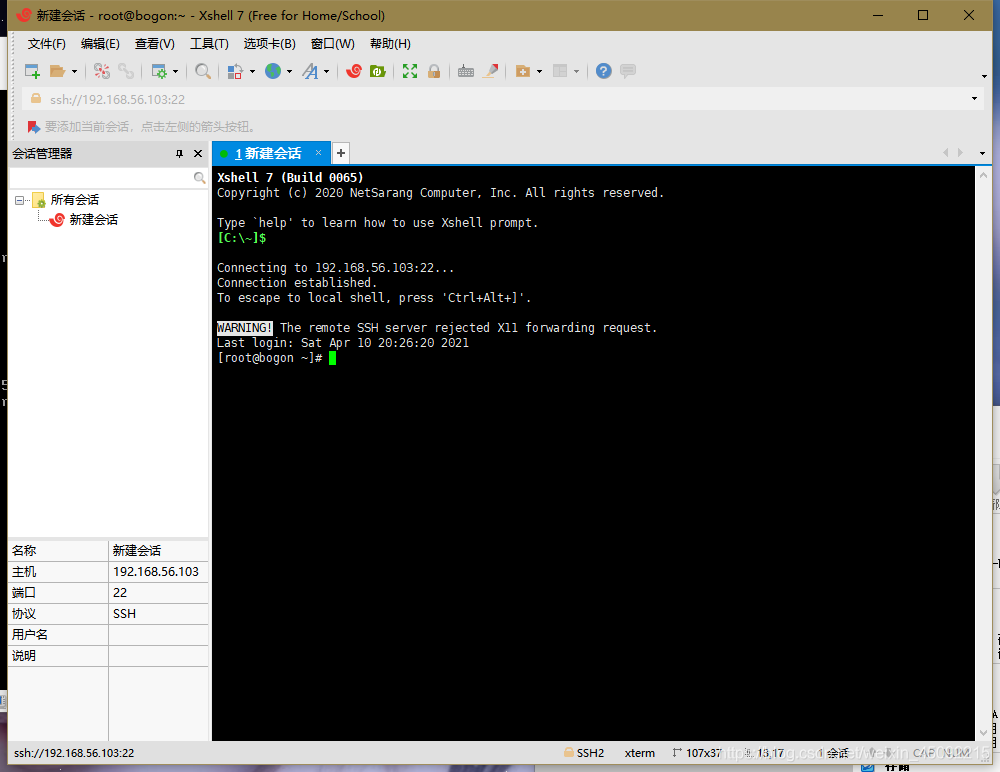
点击下图按钮,新建文件传输,自动调用Xftp进行文件传输

在右侧root文件夹下新建java子文件夹,找到本地文件右键->传输,即可将两个压缩包上传到虚拟机
输入以下命令检测是否默认安装jdk,没有反馈信息说明没有安装

使用
> cd 对应文件夹路径
将目录切换到java子文件夹下,
使用如下命令开始解压jdk压缩包

通过/etc/profile 配置环境变量
[root@bogon ~]# vi /etc/profile
进入编辑模式(i),添加以下代码,然后保存退出(esc+:+wq)
#最后添加以下内容,注意查看自己的路径及jdk版本
export JAVA_HOME=/root/java/jdk-16
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
让/etc/profile文件修改后立即生效 ,可以使用如下命令:
[root@bogon ~]# source /etc/profile
检测是否安装成功:
[root@bogon ~]# java -version

ssh 必须安装并且保证 sshd一直运行,以便用Hadoop 脚本管理远端Hadoop守护进程
检查是否安装ssh服务:
> [root@bogon ~]# rpm -qa|grep ssh
若已经安装会显示相应版本

没有安装,使用以下命令安装
[root@bogon ~]# yum install openssh-server
开启sshd服务
[root@bogon ~]# sudo service sshd start
为了免去每次开启 CentOS 时,都要手动开启 sshd 服务,可以将 sshd 服务添加至自启动列表中,输入
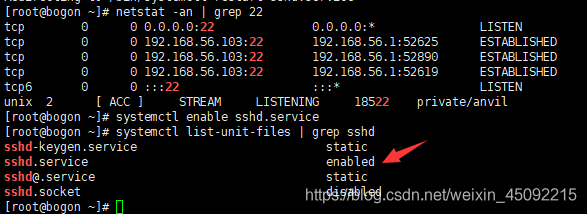
[root@bogon ~]# systemctl enable sshd.service
可以通过输入
[root@bogon ~]# systemctl list-unit-files | grep sshd
查看是否开启了sshd 服务自启动
为了获取Hadoop的发行版,从Apache的某个镜像服务器上下载最近的稳定发行版,
这里我们使用安装包中的稳定版hadoop-1.0.3.tar.gz
如之前解压jdk操作一样,将放置在java文件夹下的hadoop-1.0.3.tar.gz解压
具体操作为终端切换到java路径下,使用以下命令解压压缩包
tar -zxvf hadoop-1.0.3.tar.gz
解压结果如下

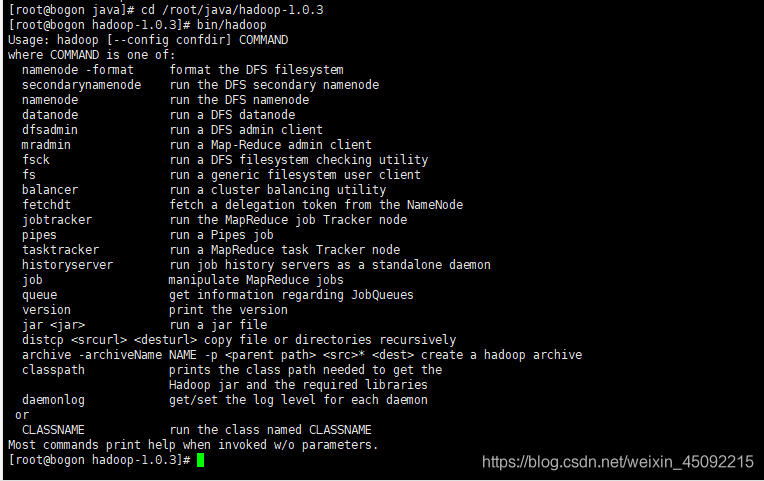
尝试如下命令:
[root@bogon java]# cd /root/java/hadoop-1.0.3 [root@bogon hadoop-1.0.3]# bin/hadoop
将会显示hadoop 脚本的使用文档
默认情况下,Hadoop被配置成以非分布式模式运行的一个独立Java进程。这对调试非常有帮助,
以下命令即运行了一次hadoop程序并获取了输出。
下面的实例将已解压的 conf 目录拷贝作为输入,查找并显示匹配给定正则表达式的条目,输出写入到指定的output目录
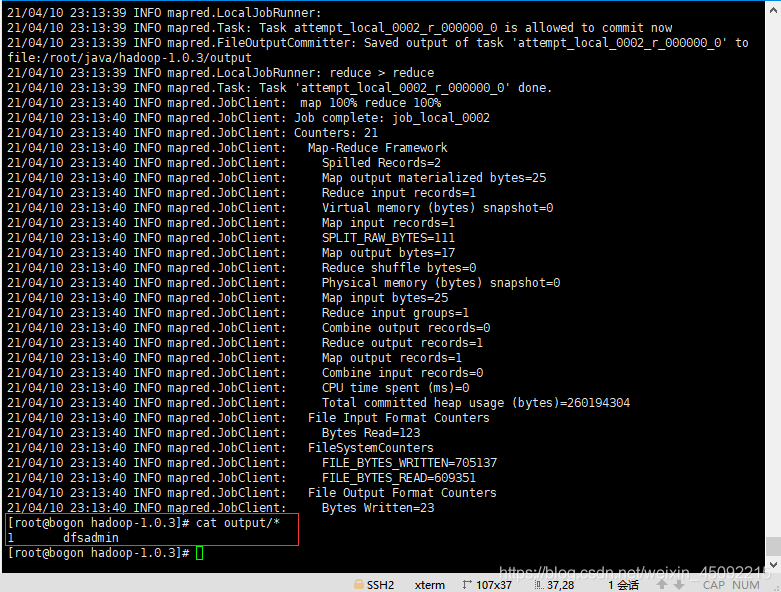
[root@bogon hadoop-1.0.3]# mkdir input [root@bogon hadoop-1.0.3]# cp conf/*.xml input [root@bogon hadoop-1.0.3]# bin/hadoop jar hadoop-examples-1.0.3.jar grep input output 'dfs[a-z.]+' [root@bogon hadoop-1.0.3]# cat output/*
以下显示该hadoop程序运行结果



到此这篇关于VirtualBox安装CentOS及JDK、Hadoop的安装与配置详细教程的文章就介绍到这了,更多相关VirtualBox CentOS安装配置JDK、Hadoop内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!




