docker容器下搭建kong的集群很简单,官网介绍的也很简单,初学者也许往往不知道如何去处理,经过本人的呕心沥血的琢磨,终于搭建出来了。
主要思想:不同的kong连接同一个数据库(就这么一句话)
难点:如何在不同的主机上用kong连接同一数据库
要求:
1、两台主机 172.16.100.101 172.16.100.102
步骤:
1、在101上安装数据库(这里就用cassandra)
docker run -d --name kong-database \
-p 9042:9042 \
cassandra:latest
2、迁移数据库(可以理解初始化数据库)
docker run --rm \
--link kong-database:kong-database \
-e "KONG_DATABASE=cassandra" \
-e "KONG_PG_HOST=kong-database" \
-e "KONG_CASSANDRA_CONTACT_POINTS=kong-database" \
kong:latest kong migrations up
3、安装kong
docker run -d --name kong \
--link kong-database:kong-database \
-e "KONG_DATABASE=cassandra" \
-e "KONG_PG_HOST=kong-database" \
-e "KONG_CASSANDRA_CONTACT_POINTS=kong-database" \
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \
-e "KONG_PROXY_ERROR_LOG=/dev/stderr" \
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \
-p 8000:8000 \
-p 8443:8443 \
-p 8001:8001 \
-p 8444:8444 \
kong:latest
注意:以上三部都是在101上完成的,且官网上都有https://getkong.org/install/docker/?_ga=2.68209937.1607475054.1519611673-2089953626.1519354770,接下来的第四步则是在另一主机102上完成,同一主机上可以用link,不同主机的容器关联就不能使用link了,如下配置即可
4、在102上安装另一个kong,实现多节点kong集群
docker run -d --name kong\
-e "KONG_DATABASE=cassandra" \
-e "KONG_PG_HOST=kong-database" \
-e "KONG_CASSANDRA_CONTACT_POINTS=172.16.100.101" \
-e "KONG_PROXY_ACCESS_LOG=/dev/stdout" \
-e "KONG_ADMIN_ACCESS_LOG=/dev/stdout" \
-e "KONG_PROXY_ERROR_LOG=/dev/stderr" \
-e "KONG_ADMIN_ERROR_LOG=/dev/stderr" \
-p 8000:8000 \
-p 8443:8443 \
-p 8001:8001 \
-p 8444:8444 \
kong:latest
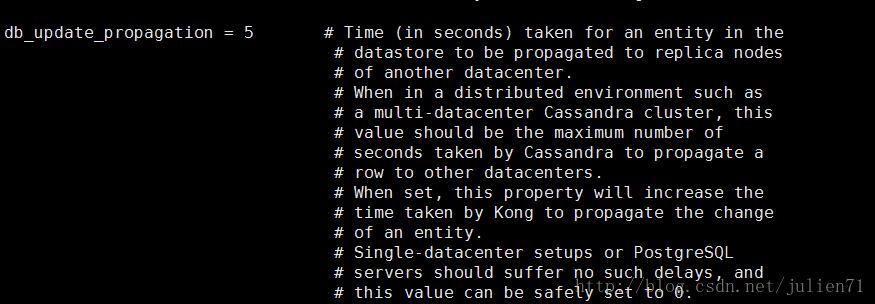
5、这里使用的是cassandra数据库,所以需要修改一个配置 db_update_propagation 这个参数,默认是0,可以改成 5,进入容器
docker exec -it kong bash //进入kong容器
cd etc/kong //进入该目录下
cp kong.conf.default kong.conf //复制kong.conf.default文件为kong.conf文件
vi kong.conf //修改db_update_propagation这个配置项
exit //退出空容器
docker restart kong //重新启动kong
注:101和102上的kong都需要修改这个配置项,关于db_update_propagation配置项的介绍可以去官网看下
6、验证kong集群
可以在101上注册一个api如下
curl -i -X POST \
--url http://172.16.100.101:8001/apis/ \
--data 'name=example-api' \
--data 'hosts=example.com' \
--data 'upstream_url=http://mockbin.org'
然后查询这个api是否注册成功:
curl -i http://172.16.100.101:8001/apis/example-api
返回如下:

你也可以通过102机器主机进行查询:
curl -i http://172.16.100.102:8001/apis/example-api
如果也返回和上面一样的结果说明可以访问同一个api了,api信息是保存在数据库中的,也是就说可以访问同一个数据库了,这样你的kong集群也就搭建成功了,希望对你有所帮助。
补充知识:使用docker-compose创建hadoop集群
下载docker镜像
首先下载需要使用的五个docker镜像
docker pull bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8
docker pull bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
docker pull bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8
docker pull bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8
docker pull bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
设置hadoop配置参数
创建 hadoop.env 文件,内容如下:
CORE_CONF_fs_defaultFS=hdfs://namenode:8020
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource___tracker_address=resourcemanager:8031
创建docker-compose文件
创建 docker-compose.yml 文件,内如如下:
version: "2"
services:
namenode:
image: bde2020/hadoop-namenode:1.1.0-hadoop2.7.1-java8
container_name: namenode
volumes:
- hadoop_namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:1.1.0-hadoop2.7.1-java8
container_name: resourcemanager
depends_on:
- namenode
- datanode1
- datanode2
- datanode3
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:1.1.0-hadoop2.7.1-java8
container_name: historyserver
depends_on:
- namenode
- datanode1
- datanode2
- datanode3
volumes:
- hadoop_historyserver:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:1.1.0-hadoop2.7.1-java8
container_name: nodemanager1
depends_on:
- namenode
- datanode1
- datanode2
- datanode3
env_file:
- ./hadoop.env
datanode1:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode1
depends_on:
- namenode
volumes:
- hadoop_datanode1:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode2:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode2
depends_on:
- namenode
volumes:
- hadoop_datanode2:/hadoop/dfs/data
env_file:
- ./hadoop.env
datanode3:
image: bde2020/hadoop-datanode:1.1.0-hadoop2.7.1-java8
container_name: datanode3
depends_on:
- namenode
volumes:
- hadoop_datanode3:/hadoop/dfs/data
env_file:
- ./hadoop.env
volumes:
hadoop_namenode:
hadoop_datanode1:
hadoop_datanode2:
hadoop_datanode3:
hadoop_historyserver:
创建并启动hadoop集群
sudo docker-compose up
启动hadoop集群后,可以使用下面命令查看一下hadoop集群的容器信息
# 查看集群包含的容器,以及export的端口号
sudo docker-compose ps
Name Command State Ports
------------------------------------------------------------
datanode1 /entrypoint.sh /run.sh Up 50075/tcp
datanode2 /entrypoint.sh /run.sh Up 50075/tcp
datanode3 /entrypoint.sh /run.sh Up 50075/tcp
historyserver /entrypoint.sh /run.sh Up 8188/tcp
namenode /entrypoint.sh /run.sh Up 50070/tcp
nodemanager1 /entrypoint.sh /run.sh Up 8042/tcp
resourcemanager /entrypoint.sh /run.sh Up 8088/tc
# 查看namenode的IP地址
sudo docker inspect namenode | grep IPAddress
也可以通过 http://:50070 查看集群状态。
提交作业
要提交作业,我们首先需要登录到集群中的一个节点,这里我们就登录到namenode节点。
sudo docker exec -it namenode /bin/bash
准备数据并提交作业
cd /opt/hadoop-2.7.1
# 创建用户目录
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/root
# 准备数据
hdfs dfs -mkdir input
hdfs dfs -put etc/hadoop/*.xml input
# 提交作业
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+'
# 查看作业执行结果
hdfs dfs -cat output/*
清空数据
hdfs dfs -rm input/*
hdfs dfs -rmdir input/
hdfs dfs -rm output/*
hdfs dfs -rmdir output/
停止集群
可以通过CTRL+C来终止集群,也可以通过 “sudo docker-compose stop”。
停止集群后,创建的容器并不会被删除,此时可以使用 “sudo docker-compose rm” 来删除已经停止的容器。也可以使用 “sudo docker-compose down” 来停止并删除容器。
删除容器后,使用 “sudo docker volume ls” 可以看到上面集群使用的volume信息,我们可以使用 “sudo docker rm ” 来删除。
以上这篇使用docker搭建kong集群操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
