前言
本文主要介绍了关于ubantu 16.4 Hadoop完全分布式搭建的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧
一个虚拟机
1.以 NAT网卡模式 装载虚拟机
2.最好将几个用到的虚拟机修改主机名,静态IP /etc/network/interface,这里 是 s101 s102 s103 三台主机 ubantu,改/etc/hostname文件
3.安装ssh
在第一台主机那里s101 创建公私密匙
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
>cd .ssh
>cp id_rsa.pub >authorized_keys 创建密匙库
将id_rsa.pub传到其他主机上,到.ssh目录下
通过 服务端 nc -l 8888 >~/.ssh/authorized_keys
客户端 nc s102 8888 <id_rsa.pub
开始安装Hadoop/jdk
1、安装VM-tools 方便从win 10 拖拉文件到ubantu
2、创建目录 /soft
3、改变组 chown ubantu:ubantu /soft 方便传输文件有权限
4、将文件放入到/soft (可以从桌面cp/mv src dst)
tar -zxvf jdk或hadoop 自动创建解压目录
配置安装环境 (/etc/environment)
1.添加 JAVA_HOME=/soft/jdk-...jdk目录
2.添加 HADOOP_HOME=/soft/hadoop(Hadoop目录)
3.在path里面加/soft/jdk-...jdk/bin:/soft/hadoop/bin/:/soft/hadoop/sbin
4.通过 java -version 查看有版本号 成功
5.hadoop version 有版本号 成功
开始配置HDFS四大文件 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s101:9000</value>
</property>
</configuration>
2.hdfs-site.xml
<configuration>
<!-- Configurations for NameNode: -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s101:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>s101:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/data/hdfs/checkpoint</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/data/hdfs/edits</value>
</property>
</configuration>
3. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s101</value>
</property>
</configuration>
到此成功一半。。。。。。。。。。。。。。
创建文件夹
mkdir /data/hdfs/tmp
mkdir /data/hdfs/var
mkdir /data/hdfs/logs
mkdir /data/hdfs/dfs
mkdir /data/hdfs/data
mkdir /data/hdfs/name
mkdir /data/hdfs/checkpoint
mkdir /data/hdfs/edits
记得将目录权限修改
- sudo chown ubantu:ubantu /data
接下来传输 /soft文件夹到其他主机
创建 xsync可执行文件
sudo touch xsync
sudo chmod 777 xsync 权限变成可执行文件
sudo nano xsync
#!/bin/bash
pcount=$#
if((pcount<1));then
echo no args;
exit;
fi
p1=$1;
fname=`basename $p1`
pdir=`cd -P $(dirname $p1);pwd`
cuser=`whoami`
for((host=102 ; host<105 ;host=host+1));do
echo --------s$host--------
rsync -rvl $pdir/$fname $cuser@s$host:$pdir
done
xsync /soft-------->就会传文件夹到其他主机
xsync /data
创建 xcall 向其他主机传命令
#!/bin/bash
pcount=$#
if((pcount<1));then
echo no args;
exit;
fi
echo --------localhost--------
$@
for ((host=102;host<105;host=host+1));do
echo --------$shost--------
ssh s$host $@
done
别着急 快结束了 哈
还得配置 workers问价
- 将需要配置成数据节点(DataNode)的主机名放入其中,一行一个
注意重点来了
先格式化 hadoop -namenode -format
再 启动 start-all.sh
查看进程 xcall jps
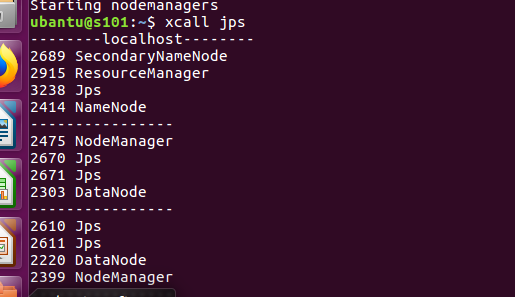
进入网页
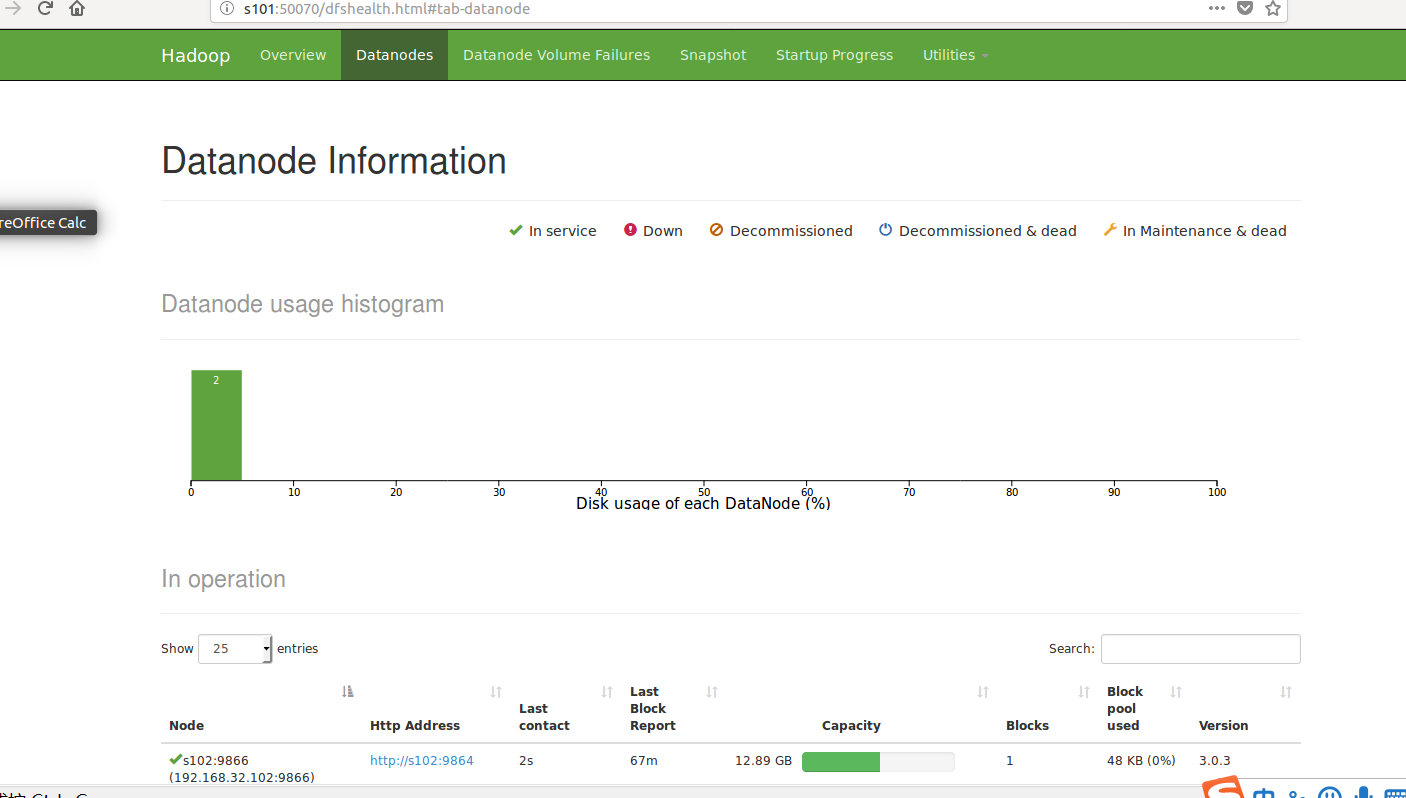
是不是很想牛泪,成功了耶!!!
中间出现了很多问题
1, rsync 权限不够 :删除文件夹 更改文件夹权限chown
2.学会看日志 log
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对脚本之家的支持。


