在做项目的时候,需求添加全文搜索,选择了lucene.net方向,调研了一下,基本实现了需求,现在将它分享给大家。理解不深请多多包涵。
在完成需求的时候,查看的大量的资料,本文不介绍详细的lucene.net工程建立,只介绍如何对文档进行全文搜索。对于如何建立lucene.net的工程请大家访问
使用lucene.net搜索分为两个部分,首先是创建索引,创建文本内容的索引,其次是根据创建的索引进行搜索。那么如何对文档进行索引呢,主要是对文档的内容进行索引,关键是提取出文档的内容,按照常规实现,由简到难,提取txt格式的文本相对比较简单,如果实现了提取txt文本,接下来就容易多了,万丈高楼平地起,这就是地基。
1.首先创建ASP.NET页面。

这是一个极其简单的页面,创建页面之后,双击各个按钮生成相应的点击事件,在相应的点击事件中实现程序设计。
2.实现索引部分。
前面已经说到了,索引主要是根据文本内容建立索引,所以要提取文本内容。创建提取txt格式文档文本内容的函数。
复制代码 代码如下:
//提取txt文件
public static string FileReaderAll(FileInfo fileName)
{
//读取文本内容,并且默认编码格式,防止出现乱码
StreamReader reader = new StreamReader(fileName.FullName, System.Text.Encoding.Default);
string line = "";
string temp = "";
//循环读取文本内容
while ((line = reader.ReadLine()) != null)
{
temp += line;
}
reader.Close();
//返回字符串,用于lucene.net生成索引
return temp;
}
文本内容已经提取出来了,接下来要根据提取的内容建立索引
复制代码 代码如下:
protected void Button2_Click(object sender, EventArgs e)
{
//判断存放文本的文件夹是否存在
if (!System.IO.Directory.Exists(filesDirectory))
{
Response.Write("script>alert('指定的目录不存在');/script>");
return;
}
//读取文件夹内容
DirectoryInfo dirInfo = new DirectoryInfo(filesDirectory);
FileInfo[] files = dirInfo.GetFiles("*.*");
//文件夹判空
if (files.Count() == 0)
{
Response.Write("script>alert('Files目录下没有文件');/script>");
return;
}
//判断存放索引的文件夹是否存在,不存在创建
if (!System.IO.Directory.Exists(indexDirectory))
{
System.IO.Directory.CreateDirectory(indexDirectory);
}
//创建索引
IndexWriter writer = new IndexWriter(FSDirectory.Open(new DirectoryInfo(indexDirectory)),
analyzer, true, IndexWriter.MaxFieldLength.LIMITED);
for (int i = 0; i files.Count(); i++)
{
string str = "";
FileInfo fileInfo = files[i];
//判断文件格式,为以后其他文件格式做准备
if (fileInfo.FullName.EndsWith(".txt") || fileInfo.FullName.EndsWith(".xml"))
{
//获取文本
str = FileReaderAll(fileInfo);
}
Lucene.Net.Documents.Document doc = new Lucene.Net.Documents.Document();
doc.Add(new Lucene.Net.Documents.Field("FileName", fileInfo.Name, Lucene.Net.Documents.Field.Store.YES, Lucene.Net.Documents.Field.Index.ANALYZED));
//根据文本生成索引
doc.Add(new Lucene.Net.Documents.Field("Content", str, Lucene.Net.Documents.Field.Store.YES, Lucene.Net.Documents.Field.Index.ANALYZED));
doc.Add(new Lucene.Net.Documents.Field("Path", fileInfo.FullName, Lucene.Net.Documents.Field.Store.YES, Lucene.Net.Documents.Field.Index.NO));
//添加生成的索引
writer.AddDocument(doc);
writer.Optimize();
}
writer.Dispose();
Response.Write("script>alert('索引创建成功');/script>");
}
3.索引创建完了,接下来就是搜索,搜索只要按照固定的格式书写不会出现错误。
复制代码 代码如下:
protected void Button1_Click(object sender, EventArgs e)
{
//获取关键字
string keyword = TextBox1.Text.Trim();
int num = 10;
//关键字判空
if (string.IsNullOrEmpty(keyword))
{
Response.Write("script>alert('请输入要查找的关键字');/script>");
return;
}
IndexReader reader = null;
IndexSearcher searcher = null;
try
{
reader = IndexReader.Open(FSDirectory.Open(new DirectoryInfo(indexDirectory)), true);
searcher = new IndexSearcher(reader);
//创建查询
PerFieldAnalyzerWrapper wrapper = new PerFieldAnalyzerWrapper(analyzer);
wrapper.AddAnalyzer("FileName", analyzer);
wrapper.AddAnalyzer("Path", analyzer);
wrapper.AddAnalyzer("Content", analyzer);
string[] fields = { "FileName", "Path", "Content" };
QueryParser parser = new MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields, wrapper);
//根据关键字查询
Query query = parser.Parse(keyword);
TopScoreDocCollector collector = TopScoreDocCollector.Create(num, true);
searcher.Search(query, collector);
//这里会根据权重排名查询顺序
var hits = collector.TopDocs().ScoreDocs;
int numTotalHits = collector.TotalHits;
//以后就可以对获取到的collector数据进行操作
for (int i = 0; i hits.Count(); i++)
{
var hit = hits[i];
Lucene.Net.Documents.Document doc = searcher.Doc(hit.Doc);
Lucene.Net.Documents.Field fileNameField = doc.GetField("FileName");
Lucene.Net.Documents.Field pathField = doc.GetField("Path");
Lucene.Net.Documents.Field contentField = doc.GetField("Content");
//在页面循环输出表格
strTable.Append("tr>");
strTable.Append("td>" + fileNameField.StringValue + "/td>");
strTable.Append("/tr>");
strTable.Append("tr>");
strTable.Append("td>" + pathField.StringValue + "/td>");
strTable.Append("/tr>");
strTable.Append("tr>");
strTable.Append("td>" + contentField.StringValue.Substring(0, 300) + "/td>");
strTable.Append("/tr>");
}
}
finally
{
if (searcher != null)
searcher.Dispose();
if (reader != null)
reader.Dispose();
}
}
现在整个lucene.net搜索全文的过程就建立完了,现在可以搜索txt格式的文件,搜索其他格式的文件在以后添加,主要核心思想就是提取各个不同格式文件的文本内容。
显示效果如下:
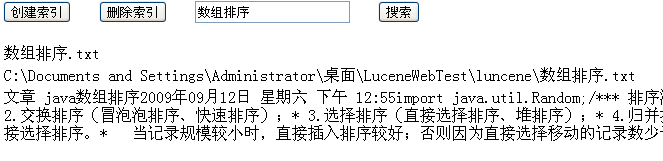
在以后的博文里继续接受搜索其他格式的文档。
您可能感兴趣的文章:- Lucene.Net实现搜索结果分类统计功能(中小型网站)
- Java实现lucene搜索功能的方法(推荐)
- 基于Lucene的Java搜索服务器Elasticsearch安装使用教程
- 使用Java的Lucene搜索工具对检索结果进行分组和分页
- 使用Lucene.NET实现站内搜索
- 使用Lucene实现一个简单的布尔搜索功能




