| 字符 | ASCII | Unicode | UTF-8 |
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | X | 01001110 00101101 | 11100100 10111000 10101101 |
二、计算机系统中的编码应用
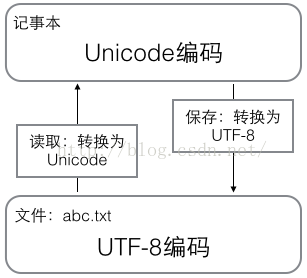
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码;用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
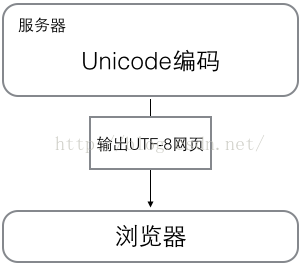
所以你看到很多网页的源码上会有类似meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
三、Java中的编码问题
直接写一个demo来看看eclipse中java项目的编码是怎么样的吧。
1、字符串转为字节序列
public class EncodeDemo {
public static void main(String[] args) {
// TODO Auto-generated method stub
String s="云开de立夏";
byte[] bytes1=s.getBytes();//这是把字符串转换成字符数组,转换成的字节序列用的是项目默认的编码
for(byte b: bytes1)
//toHexString这个函数是把字节(转换成了Int)以16进制的方式显示
System.out.print(Integer.toHexString(b 0xff)+" ");// 0xff是为了把前面的24个0去掉只留下后八位
}
}
运行结果:

分析:可以看到这个java项目的默认编码中,汉字用2个字节表示,英文用一个字节表示。
通过查看项目的默认编码为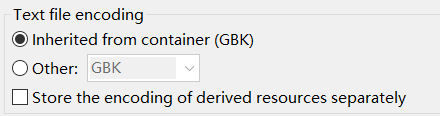 GBK。
GBK。
如果不想用项目默认的编码格式,可以用下面这种方法指定字符串转化为想要的编码格式:
byte[] bytes2=s.getBytes("utf-8");//转换成utf-8编码
for(byte b: bytes2)
//toHexString这个函数是把字节(转换成了Int)以16进制的方式显示
System.out.print(Integer.toHexString(b 0xff)+" ");// 0xff是为了把前面的24个0去掉只留下后八位
System.out.println();
byte[] bytes3=s.getBytes("utf-16be");//转换成java双字节编码,utf-16be编码
for(byte b: bytes3)
//toHexString这个函数是把字节(转换成了Int)以16进制的方式显示
System.out.print(Integer.toHexString(b 0xff)+" ");// 0xff是为了把前面的24个0去掉只留下后八位
运行结果:

分析:两个结果对比可以得出,
gbk编码: 中文占用两个字节,英文占用一个字节。
utf-8编码:中文占用三个字节,英文占用一个字节。
utf-16be编码:中文占用两个字节,英文占用两个字节。
注意:java是双字节编码,是utf-16be编码。即java中的一个字符(char)占用两个字节!
2、字节序列转为字符串
当你的字节序列是某种编码时,这个时候想把字节序列变成字符串,也需要用这种编码方式,否则会出现乱码。
String str1=new String(bytes1);//这时会使用项目默认的编码来转换,可能出现乱码 System.out.println(str1); String str2=new String(bytes2); System.out.println(str2); String str3=new String(bytes2,"utf-8"); System.out.println(str3);
运行结果:

四、文本文件(txt)的编码问题
文本文件就是字节序列,可以是任意编码的字节序列。
如果我们在中文机器上直接创建文本文件,那么该文件只认识ANSI编码(例如直接在电脑中右键创建文本文件)。
这里要注意:只有直接创建文本文件时,该文件的编码只认识ANSI,但是文本文件本身是可以放任意编码的字节序列。
注意:中文系统下,ANSI编码即是GBK编码。
这里举个例子:
我们在eclipse新建一个项目,把它的默认编码改为utf-8
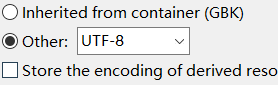
那么对于这个项目而言,它只认识utf-8的编码文件。
接下来,我们在这个项目中新建一个文本文件utf-8.txt,并在里面输入内容如下:


如果直接把这个文本文件拷贝到其他项目中(默认为GBK编码),里面的内容将会变成乱码!因为编码不一样!
但是如果是将里面的内容复制粘贴过去,系统会自动转化为相应的编码,是不会出现乱码的。

注意:如果把这个文本文件拷贝到其他地方(比如系统的桌面)上,它不会出现乱码!!因为文本文件可以是任意的编码序列,系统在读取文本文件时会自动转化为相应的编码格式。
了解文件的编码有什么用呢??在Java的IO流中,我们需要对文件进行读写,使用字节流进行读写的时候,就必须根据不同的编码方式进行读写。因为不同编码方式的各个字符所占用的字节数不同,我们要按照实际情况进行操作。
以上这篇老生常谈计算机中的编码问题(必看篇)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
