项目开发中hadoop一直装在虚拟机上,最近要迁移到服务器上。记录下迁移过程。
一、为虚拟机添加一块新的硬盘
虚拟机的初始硬盘只有30G,容不开要导出的数据。两种方式,一是给虚拟机扩容;二是为虚拟机添加一块新的硬盘。这里采取第二种方式。
1、添加虚拟硬盘
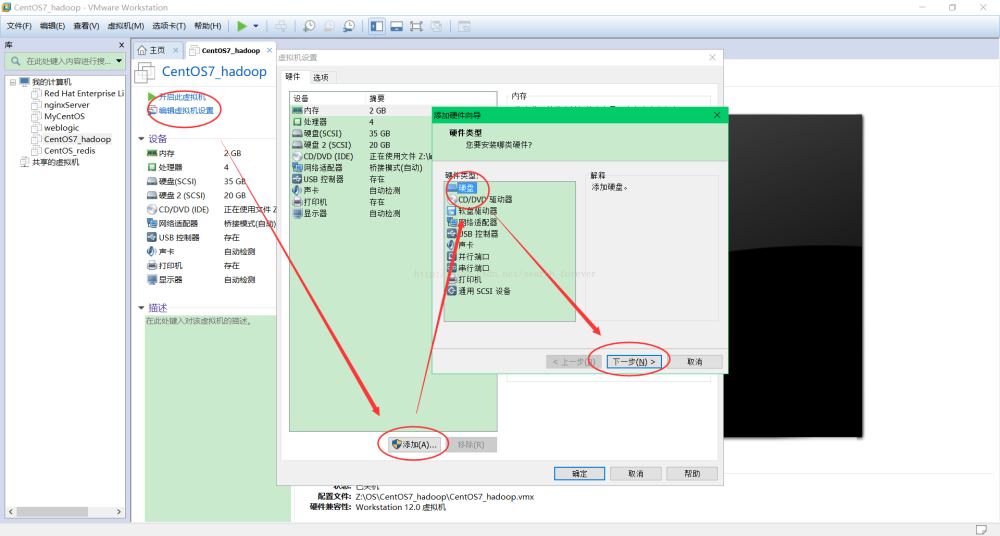
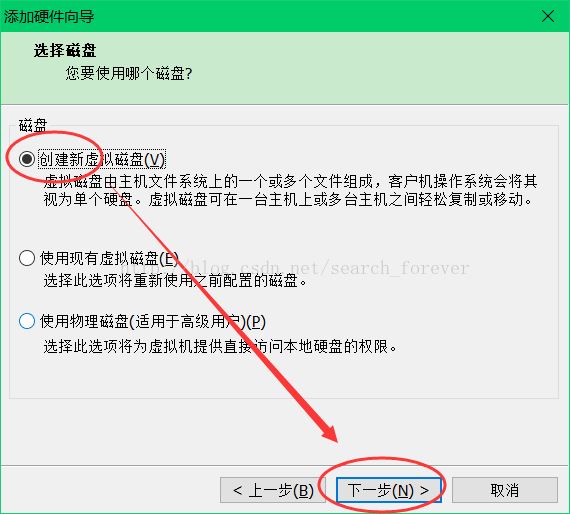
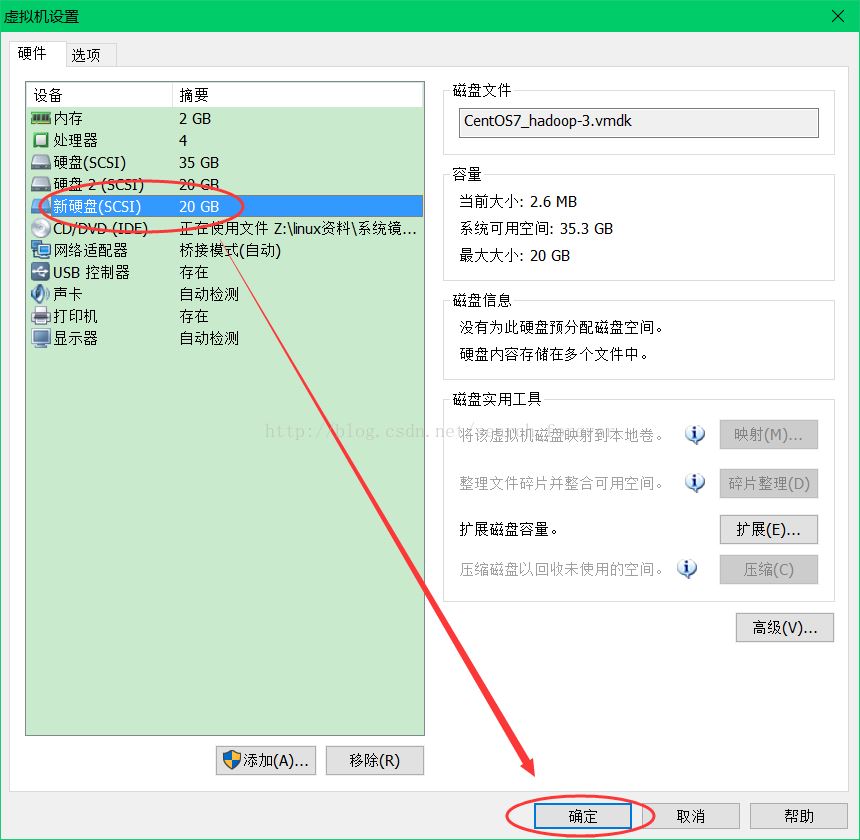
至此,添加硬盘成功。
2、将硬盘分区
要使用一块新的硬盘,需要先将硬盘分区,然后挂在文件系统上才能使用。
这里普及一下linux的文件系统与硬盘以及分区的关系。按照一个“由硬到软”的顺序来讲,首先是硬盘,是物理的;我们要使用这个物理硬盘,需要将物理硬盘分成一个一个的分区;而我们在使用操作系统时,则通过文件系统来操作文件。文件系统这个“软件“是通过分区与硬盘这个“硬件”进行联系的:硬盘分成区后,以分区的形式挂在文件系统上。
举例比较windows与linux文件系统的区别:
对于windows来讲,比如我们的电脑上只安装了一块硬盘,这个硬盘分了四个区,对应我们文件系统中的CDEF盘。即四个分区在我们使用者看来是平级的。这时如果添加了一个
对于linux来讲,硬盘也是以分区的形式挂载在文件系统上。这点与windows一致。不同的是,windows有多个文件系统树(C:D:E:F:),而linux只有一个文件系统树,也就是我们看到的,所有的目录以及文件都是在根目录 / 下的。那么linux是怎么挂的呢?linux会将不同的分区挂在不同的目录下。
如图:
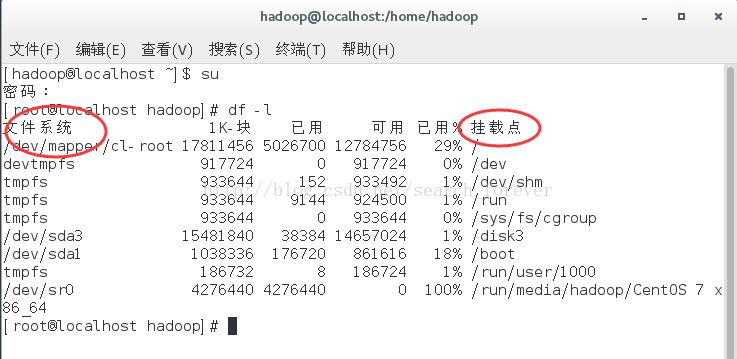
图中,文件系统其实就是我们上边讲的分区,这些文件系统(分区)共同组成了我们linux整个的文件系统。这里注意,其实文件系统与分区是统一的,可以认为分区是文件系统的载体,我们上边讲它们两者的关系,只是为了进一步帮助理解。那么既然分区是挂在linux的基于根目录的这棵“树”上的,我们就将分区挂的这个目录称为挂载点。如上。
下边我们来具体讲解一下关于将硬盘分区的命令:
a、使用:fdisk -l 命令查看硬盘及分区信息,如图:
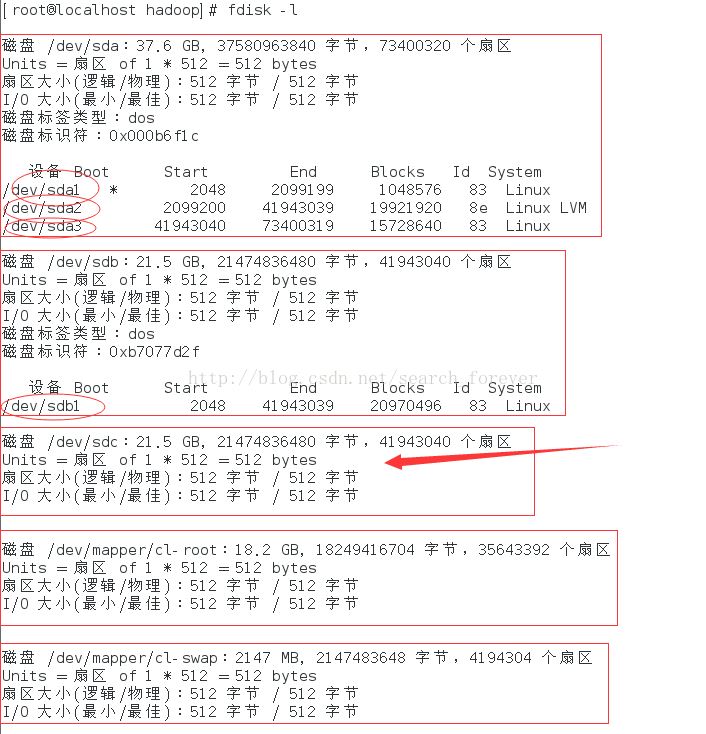
图中,使用矩形围起来的是硬盘,一般硬盘会按照sda、sdb、sdc的顺序依次添加。下边两块硬盘暂时不要考虑。
使用椭圆圈起来的是分区,如硬盘sda有三个分区,分别是sda1、sda2、sda3。
可以看到箭头指向的硬盘sdc没有分区,这意味着这块硬盘尚未被使用,这就是我们新添加的硬盘。
b、通过 fdisk /dev/sdc 对新硬盘进行分区

输入m可以打印我们的操作菜单,注意上边红线圈出 的命令,n代表新建一个分区,p代表打印当前硬盘的分区表,w代表向硬盘写入分区表。接下来我们依次执行。如图:

输入n,新建一个分区,两个选项,p代表主分区,e代表扩展分区,选择p主分区;第二次输入p是为了打印分区表,可以看到分区sdc1创建成功。创建过程中的分区好,起始扇区,last扇区使用默认值直接回车即可。最后输入w,写入分区。
c、使用 mkfs -t ext4 /dev/sdc1 将新分区格式化成ext4的格式
如图:

d、通过 mount /dev/sdc1 /disk5 将新的分区sdc1挂载到目录disk5下边
如图:

最后,我们通过df -lh /disk5 命令查看目录disk5,发现其确实是新的分区sdc1,挂在成功。如此,便可正常使用新加的硬盘了。
小结:用到了 fdisk df mkfs mount 等几个命令,注意复习。
二、hadoop的命令的使用
1、首先需要执行命令使hadoop命令能够被识别。
export PATH=$PATH:/home/hadoop/hadoop-2.5.2/bin
2、hadoop的文件系统的命令与linux的命令十分一致,下边举例说明:
hadoop fs -ls / 表示列出根目录下的所有文件(夹)
hadoop fs -put readme.txt /user/hadoop/test/ 表示将readme.txt文件上传到hdfs的/user/hadoop/test/目录下
hadoop fs -get / /hadoop_data 表示将hdfs文件系统根目录/下的所有文件(夹)导出到本地的/hadoop_data目录下
hadoop fs -rm / 表示删除hdfs文件系统中的所有文件(夹)
总结
以上所述是小编给大家介绍的hadoop迁移数据应用实例详解,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
