目录
- 内容介绍
- 一般应用场景
- 线性回归的常用方法
- 线性回归实现
- 线性回归评估指标
- 线性回归效果可视化
- 数据预测
内容介绍
以 Python 使用 线性回归 简单举例应用介绍回归分析。
线性回归是利用线性的方法,模拟因变量与一个或多个自变量之间的关系;
对于模型而言,自变量是输入值,因变量是模型基于自变量的输出值,适用于x和y满足线性关系的数据类型的应用场景。
用于预测输入变量和输出变量之间的关系,特别是当输入变量的值发生变化时,输出变量的值也随之发生变化。
回归模型正是表示从输入变量到输出变量之间映射的函数。
线性回归几乎是最简单的模型了,它假设因变量和自变量之间是线性关系的,一条直线简单明了。
一般应用场景
连续性数据的预测:例如房价预测、销售额度预测、贷款额度预测。
简单来说就是用历史的连续数据去预测未来的某个数值。
线性回归的常用方法
最小二乘法、贝叶斯岭回归、弹性网络回归、支持向量机回归、支持向量机回归等。
线性回归实现
import numpy as np # numpy库
from sklearn.linear_model import BayesianRidge, LinearRegression, ElasticNet,Lasso # 批量导入要实现的回归算法
from sklearn.svm import SVR # SVM中的回归算法
from sklearn.ensemble.gradient_boosting import GradientBoostingRegressor # 集成算法
from sklearn.model_selection import cross_val_score # 交叉检验
from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score # 批量导入指标算法
import pandas as pd # 导入pandas
import matplotlib.pyplot as plt # 导入图形展示库
import random
# 随机生成100组包含5组特征的数据
feature = [[random.random(),random.random(),random.random(),random.random(),random.random()] for i in range(100)]
dependent = [round(random.uniform(1,100),2) for i in range(100)]
# 训练回归模型
n_folds = 6 # 设置交叉检验的次数
model_br = BayesianRidge() # 建立贝叶斯岭回归模型对象
model_lr = LinearRegression() # 建立普通线性回归模型对象
model_etc = ElasticNet() # 建立弹性网络回归模型对象
model_svr = SVR() # 建立支持向量机回归模型对象
model_la = Lasso() # 建立支持向量机回归模型对象
model_gbr = GradientBoostingRegressor() # 建立梯度增强回归模型对象
model_names = ['BayesianRidge', 'LinearRegression', 'ElasticNet', 'SVR', 'Lasso','GBR'] # 不同模型的名称列表
model_dic = [model_br, model_lr, model_etc, model_svr,model_la, model_gbr] # 不同回归模型对象的集合
cv_score_list = [] # 交叉检验结果列表
pre_y_list = [] # 各个回归模型预测的y值列表
for model in model_dic: # 读出每个回归模型对象
scores = cross_val_score(model, feature, dependent, cv=n_folds) # 将每个回归模型导入交叉检验模型中做训练检验
cv_score_list.append(scores) # 将交叉检验结果存入结果列表
pre_y_list.append(model.fit(feature, dependent).predict(feature)) # 将回归训练中得到的预测y存入列表
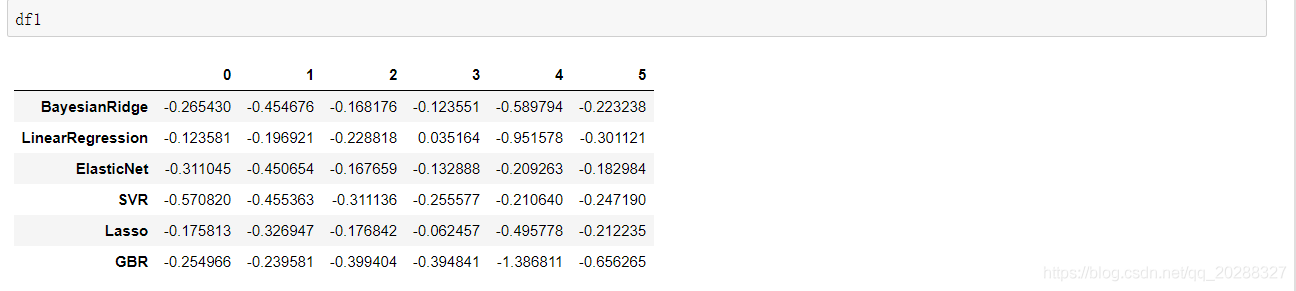
线性回归评估指标
model_gbr:拟合贝叶斯岭模型,以及正则化参数lambda(权重的精度)和alpha(噪声的精度)的优化。
model_lr:线性回归拟合系数w=(w1,…)的线性模型,wp)将观测到的目标与线性近似预测的目标之间的残差平方和降到最小。
model_etc:以L1和L2先验组合为正则元的线性回归。
model_svr:线性支持向量回归。
model_la:用L1先验作为正则化器(又称Lasso)训练的线性模型
# 模型效果指标评估
model_metrics_name = [explained_variance_score, mean_absolute_error, mean_squared_error, r2_score] # 回归评估指标对象集
model_metrics_list = [] # 回归评估指标列表
for i in range(6): # 循环每个模型索引
tmp_list = [] # 每个内循环的临时结果列表
for m in model_metrics_name: # 循环每个指标对象
tmp_score = m(dependent, pre_y_list[i]) # 计算每个回归指标结果
tmp_list.append(tmp_score) # 将结果存入每个内循环的临时结果列表
model_metrics_list.append(tmp_list) # 将结果存入回归评估指标列表
df1 = pd.DataFrame(cv_score_list, index=model_names) # 建立交叉检验的数据框
df2 = pd.DataFrame(model_metrics_list, index=model_names, columns=['ev', 'mae', 'mse', 'r2']) # 建立回归指标的数据框

线性回归效果可视化
# 模型效果可视化
plt.figure() # 创建画布
plt.plot(np.arange(len(feature)), dependent, color='k', label='true y') # 画出原始值的曲线
color_list = ['r', 'b', 'g', 'y', 'p','c'] # 颜色列表
linestyle_list = ['-', '.', 'o', 'v',':', '*'] # 样式列表
for i, pre_y in enumerate(pre_y_list): # 读出通过回归模型预测得到的索引及结果
plt.plot(np.arange(len(feature)), pre_y_list[i], color_list[i], label=model_names[i]) # 画出每条预测结果线
plt.title('regression result comparison') # 标题
plt.legend(loc='upper right') # 图例位置
plt.ylabel('real and predicted value') # y轴标题
plt.show() # 展示图像
数据预测
# 模型应用
new_point_set = [[random.random(),random.random(),random.random(),random.random(),random.random()],
[random.random(),random.random(),random.random(),random.random(),random.random()],
[random.random(),random.random(),random.random(),random.random(),random.random()],
[random.random(),random.random(),random.random(),random.random(),random.random()]] # 要预测的新数据集
print("贝叶斯岭回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_gbr.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("普通线性回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_lr.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("弹性网络回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_etc.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("支持向量机回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_svr.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
print (50 * '-')
print("拉索回归模型预测结果:")
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_la.predict(np.array(new_point).reshape(1,-1))
print ('预测随机数值 %d 是: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息

以上就是回归预测分析python数据化运营线性回归总结的详细内容,更多关于python数据化运营线性回归的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:- python深度总结线性回归
- tensorflow基本操作小白快速构建线性回归和分类模型
- python实现线性回归算法
- python机器学习之线性回归详解
- 使用pytorch实现线性回归
- pytorch实现线性回归
- 详解TensorFlow2实现前向传播
