| 合并方法 | SQL 方法 |
|---|---|
| left | LEFT OUTER JOIN |
| right | RIGHT OUTER JOIN |
| outer | FULL OUTER JOIN |
| inner | INNER JOIN |
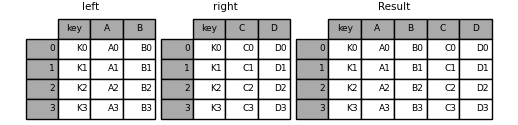
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
指定indicator=True ,可以表示具体行的连接方式:
In [60]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [61]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [62]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[62]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
如果传入字符串给indicator,会重命名indicator这一列的名字:
In [63]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column') Out[63]: col1 col_left col_right indicator_column 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only
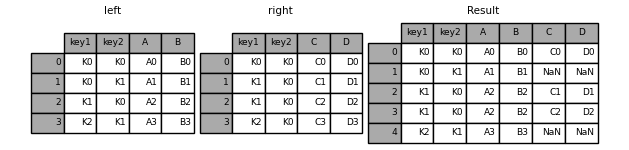
多个index进行合并:
In [112]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [114]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [116]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
支持多个列的合并:
In [117]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [118]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [119]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [120]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [121]: result = left.merge(right, on=['key1', 'key2'])
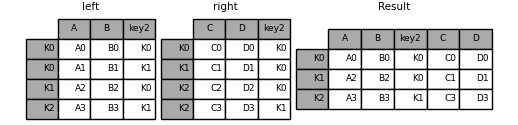
join将两个不同index的DF合并成一个。可以看做是merge的简写。
In [84]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [85]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [86]: result = left.join(right)
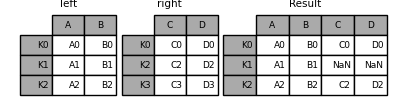
可以指定how来指定连接方式:
In [87]: result = left.join(right, how='outer')

默认join是按index来进行连接。
还可以按照列来进行连接:
In [91]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [93]: result = left.join(right, on='key')

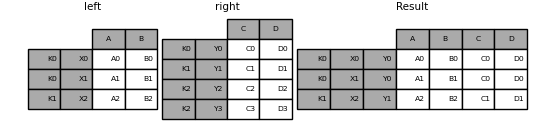
单个index和多个index进行join:
In [100]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
.....:
In [101]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [102]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=index)
.....:
In [103]: result = left.join(right, how='inner')

列名重复的情况:
In [122]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [123]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [124]: result = pd.merge(left, right, on='k')

可以自定义重复列名的命名规则:
In [125]: result = pd.merge(left, right, on='k', suffixes=('_l', '_r'))

有时候我们需要使用DF2的数据来填充DF1的数据,这时候可以使用combine_first:
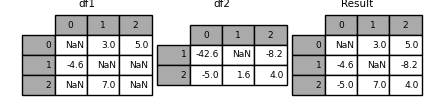
In [131]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan], .....: [np.nan, 7., np.nan]]) .....: In [132]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]], .....: index=[1, 2]) .....:
In [133]: result = df1.combine_first(df2)
到此这篇关于Pandas实现Dataframe的合并的文章就介绍到这了,更多相关Pandas Dataframe合并内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!