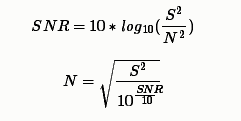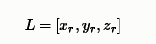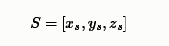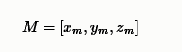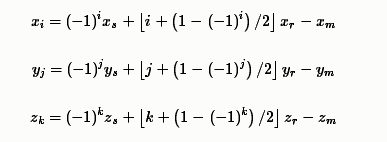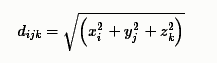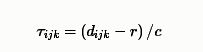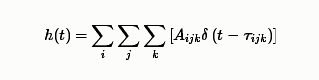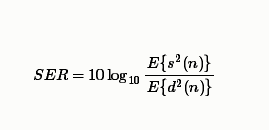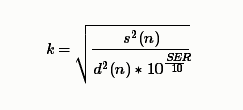目录
- 一、概述
- 二、加噪
- 2.1、第一种:控制噪声因子
- 2.2、第二种:控制信噪比
- 三、加混响
- 3.1、方法一:Pyroomacoustics实现音频加混响
- 3.2、方法二:Image Source Method 算法讲解
- 四、生成指定SER的混响
- 五、波形位移
- 六、波形拉伸
- 七、音高修正(Pitch Shifting)
一、概述
音频时域波形具有以下特征:音调,响度,质量。我们在进行数据增强时,最好只做一些小改动,使得增强数据和源数据存在较小差异即可,切记不能改变原有数据的结构,不然将产生“脏数据”,通过对音频数据进行数据增强,能有助于我们的模型避免过度拟合并变得更加通用。
我发现对声波的以下改变是有用的:Noise addition(增加噪音)、Add reverb(增加混响)、Time shifting(时移)、Pitch shifting(改变音调)和Time stretching(时间拉伸)。
本章需要使用的python库:
- matplotlib:绘制图像
- librosa:音频数据处理
- numpy:矩阵数据处理
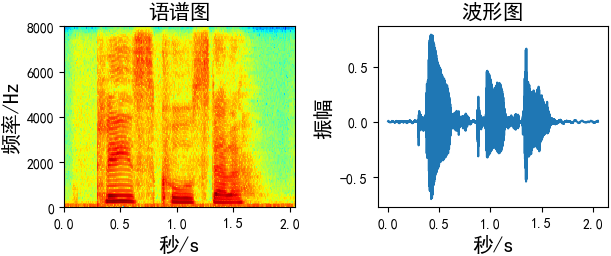
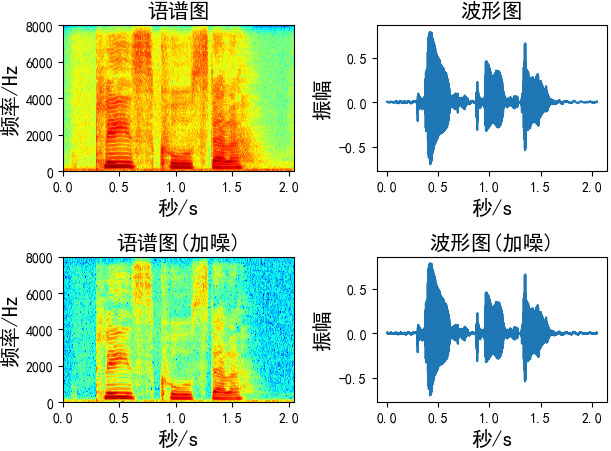
使用先画出原始语音数据的语谱图和波形图
import librosa
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示符号
fs = 16000
wav_data, _ = librosa.load("./p225_001.wav", sr=fs, mono=True)
# ########### 画图
plt.subplot(2, 2, 1)
plt.title("语谱图", fontsize=15)
plt.specgram(wav_data, Fs=16000, scale_by_freq=True, sides='default', cmap="jet")
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('频率/Hz', fontsize=15)
plt.subplot(2, 2, 2)
plt.title("波形图", fontsize=15)
time = np.arange(0, len(wav_data)) * (1.0 / fs)
plt.plot(time, wav_data)
plt.xlabel('秒/s', fontsize=15)
plt.ylabel('振幅', fontsize=15)
plt.tight_layout()
plt.show()
二、加噪
添加的噪声为均值为0,标准差为1的高斯白噪声,有两种方法对数据进行加噪
2.1、第一种:控制噪声因子
def add_noise1(x, w=0.004):
# w:噪声因子
output = x + w * np.random.normal(loc=0, scale=1, size=len(x))
return output
Augmentation = add_noise1(x=wav_data, w=0.004)
2.2、第二种:控制信噪比
通过信噪比的公式推导出噪声。
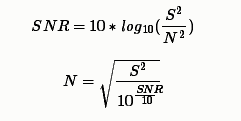
def add_noise2(x, snr):
# snr:生成的语音信噪比
P_signal = np.sum(abs(x) ** 2) / len(x) # 信号功率
P_noise = P_signal / 10 ** (snr / 10.0) # 噪声功率
return x + np.random.randn(len(x)) * np.sqrt(P_noise)
Augmentation = add_noise2(x=wav_data, snr=50)
三、加混响
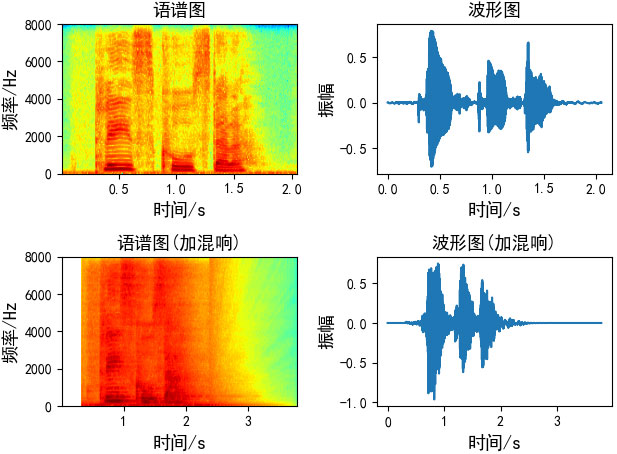
我这里使用的是Image Source Method(镜像源方法)来实现语音加混响,我想用两种方法来给大家实现,第一种是直接调用python库——Pyroomacoustics来实现音频加混响,第二种就是按照公式推导一步一步来实现,两种效果一样,想看细节的可以参考第二种方法,只想开始实现效果的可以只看第一种方法:
3.1、方法一:Pyroomacoustics实现音频加混响
首先需要安装Pyroomacoustics,这个库非常强大,感兴趣也可以多看看其他API接口
pip install Pyroomacoustics
步骤:
1.创建房间(定义房间大小、所需的混响时间、墙面材料、允许的最大反射次数、)
2.在房间内创建信号源
3.在房间内放置麦克风
4.创建房间冲击响应
5.模拟声音传播
# -*- coding:utf-8 -*-
import pyroomacoustics as pra
import numpy as np
import matplotlib.pyplot as plt
import librosa
# 1、创建房间
# 所需的混响时间和房间的尺寸
rt60_tgt = 0.5 # 所需的混响时间,秒
room_dim = [9, 7.5, 3.5] # 我们定义了一个9m x 7.5m x 3.5m的房间,米
# 我们可以使用Sabine's公式来计算壁面能量吸收和达到预期混响时间所需的ISM的最大阶数(RT60,即RIR衰减60分贝所需的时间)
e_absorption, max_order = pra.inverse_sabine(rt60_tgt, room_dim) # 返回 墙壁吸收的能量 和 允许的反射次数
# 我们还可以自定义 墙壁材料 和 最大反射次数
# m = pra.Material(energy_absorption="hard_surface") # 定义 墙的材料,我们还可以定义不同墙面的的材料
# max_order = 3
room = pra.ShoeBox(room_dim, fs=16000, materials=pra.Material(e_absorption), max_order=max_order)
# 在房间内创建一个位于[2.5,3.73,1.76]的源,从0.3秒开始向仿真中发出wav文件的内容
audio, _ = librosa.load("speech.wav",sr=16000) # 导入一个单通道语音作为源信号 source signal
room.add_source([2.5, 3.73, 1.76], signal=audio, delay=0.3)
# 3、在房间放置麦克风
# 定义麦克风的位置:(ndim, nmics) 即每个列包含一个麦克风的坐标
# 在这里我们创建一个带有两个麦克风的数组,
# 分别位于[6.3,4.87,1.2]和[6.3,4.93,1.2]。
mic_locs = np.c_[
[6.3, 4.87, 1.2], # mic 1
[6.3, 4.93, 1.2], # mic 2
]
room.add_microphone_array(mic_locs) # 最后将麦克风阵列放在房间里
# 4、创建房间冲击响应(Room Impulse Response)
room.compute_rir()
# 5、模拟声音传播,每个源的信号将与相应的房间脉冲响应进行卷积。卷积的输出将在麦克风上求和。
room.simulate()
# 保存所有的信号到wav文件
room.mic_array.to_wav("./guitar_16k_reverb_ISM.wav", norm=True, bitdepth=np.float32,)
# 测量混响时间
rt60 = room.measure_rt60()
print("The desired RT60 was {}".format(rt60_tgt))
print("The measured RT60 is {}".format(rt60[1, 0]))
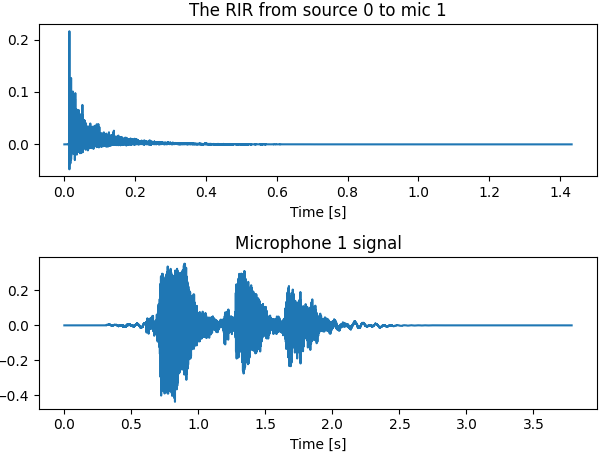
plt.figure()
# 绘制其中一个RIR. both can also be plotted using room.plot_rir()
rir_1_0 = room.rir[1][0] # 画出 mic 1和 source 0 之间的 RIR
plt.subplot(2, 1, 1)
plt.plot(np.arange(len(rir_1_0)) / room.fs, rir_1_0)
plt.title("The RIR from source 0 to mic 1")
plt.xlabel("Time [s]")
# 绘制 microphone 1 处接收到的信号
plt.subplot(2, 1, 2)
plt.plot(np.arange(len(room.mic_array.signals[1, :])) / room.fs, room.mic_array.signals[1, :])
plt.title("Microphone 1 signal")
plt.xlabel("Time [s]")
plt.tight_layout()
plt.show()
room = pra.ShoeBox(
room_dim,
fs=16000,
materials=pra.Material(e_absorption),
max_order=3,
ray_tracing=True,
air_absorption=True,
)
# 激活射线追踪
room.set_ray_tracing()
room.simulate(reference_mic=0, snr=10) # 控制信噪比
3.2、方法二:Image Source Method 算法讲解
从这里要讲算法和原理了,
代码参考:matlab版本:RIR-Generator,python版本:rir-generator
镜像源法简介:

将反射面等效为一个虚像,或者说镜像。比如说,在一个开放空间里有一面平整墙面,那么一个声源可以等效为2两个声源;一个开放空间里有两面垂直的平整墙面,那么一个声源可以等效为4个;同理三面的话是8个。原理上就是这样,但是封闭的三维空间里情况有那么点复杂,
一般来说,家里的空房间可以一定程度上近似为矩形盒子,假设房间尺寸为:
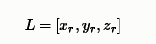
元素大小分别代表长宽高,而声源的三维坐标为
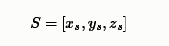
麦克风的三维坐标为
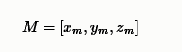
镜像声源$(i,j,k)$到麦克风距离在三个坐标轴上的位置为
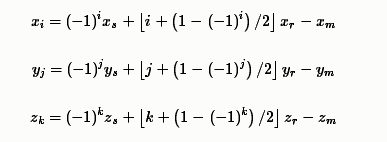
那么声源$(i,j,k)$距离麦克风的距离为
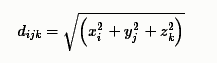
相对于直达声的到达延迟时间为
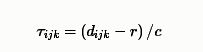
其中$c$为声速,$r$为声源到麦克风的直线距离。那么,混响效果等效为不同延迟的信号的叠加,即混响效果可以表示为一个FIR滤波器与信号源卷积的形式,此滤波器可写为如下形式
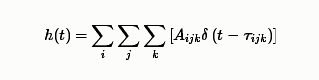
滤波器的抽头系数与镜面的反射系数与距离相关,如果每个面的反射系数不同则形式略复杂。详细代码还是要看RIR-Generator,我这里只做抛转引玉,写一个最简单的。
模拟镜像源:
房间尺寸(m):4 X 4 X 3
声源坐标(m):2 X 2 X 0
麦克风坐标(m):2 X 2 X 1.5
混响时间(s):0.2
RIR长度:512
clc;clear;
c = 340; % 声速 (m/s)
fs = 16000; % Sample frequency (samples/s)
r = [2 2 1.5]; % 麦克风位置 [x y z] (m)
s = [2 2 0]; % 扬声器位置 [x y z] (m)
L = [4 4 3]; % 房间大小 [x y z] (m)
beta = 0.2; % 混响时间 (s)
n = 512; % RIR长度
h = rir_generator(c, fs, r, s, L, beta, n);
disp(size(h)) % (1,4096)
[speech, fs] = audioread("./test_wav/p225_001.wav");
disp(size(speech)); % (46797,1)
y = conv(speech', h);
disp(length(y))
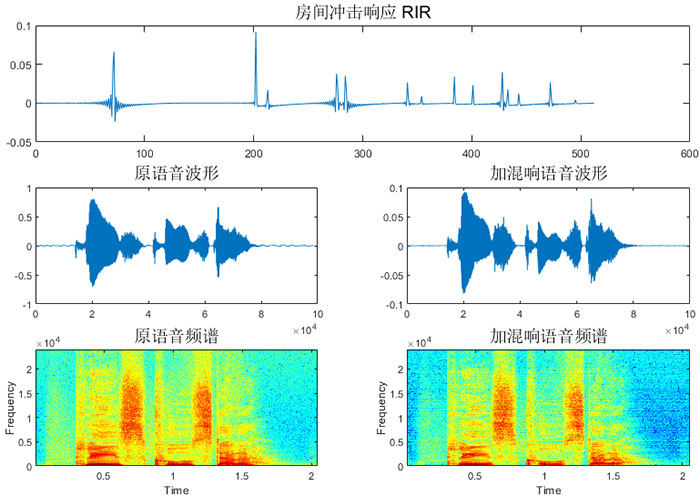
% 开始画图
figure('color','w'); % 背景色设置成白色
subplot(3,1,1)
plot(h)
title("房间冲击响应 RIR","FontSize",14)
subplot(3,2,3)
plot(speech)
title("原语音波形","FontSize",14)
subplot(3,2,4)
plot(y)
title("加混响语音波形","FontSize",14)
subplot(3,2,5)
specgram(speech,512,fs,512,256);
title("原语音频谱","FontSize",14)
subplot(3,2,6)
specgram(y,512,fs,512,256);
title("加混响语音频谱","FontSize",14)
audiowrite("./test_wav/matlab_p225_001_reverber.wav",y,fs)
四、生成指定SER的混响
SER的公式为
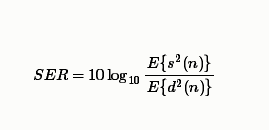
其中E是统计 期望操作,$s(n)$是近端语音,$d(n)$是远端回声,
由于我们需要根据指定的SER求混响信号,并且近端语音和远端混响都是已知的,我们只需要求得一个系数,来调整回声信号的能量大小,与远端混响相乘即可得我们想要的混响语音,即调整后的回声信号为$kd(n)$
根据以上公式,可以推导出$k$的值
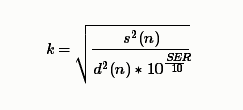
最终$kd(n)$即我们所求的指定SER的混响。
def add_echo_ser(near_speech, far_echo, SER):
"""根据指定的SER求回声
:param near_speech: 近端语音
:param far_echo: 远端回声
:param SER: 指定的SER
:return: 指定SER的回声
"""
p_near_speech = np.mean(near_speech ** 2) # 近端语音功率
p_far_echo = np.mean(far_echo ** 2) # 远端回声功率
k = np.sqrt(p_near_speech / (10 ** (SER / 10)) / p_far_echo)
return k * far_echo
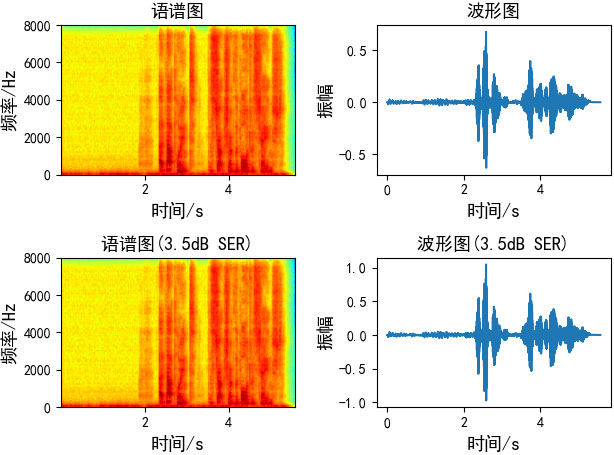
五、波形位移
语音波形移动使用numpy.roll函数向右移动shift距离
numpy.roll(a,shift,axis=None)
参数:
- a:数组
- shift:滚动的长度
- axis:滚动的维度。0为垂直滚动,1为水平滚动,参数为None时,会先将数组扁平化,进行滚动操作后,恢复原始形状
x = np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
print(np.roll(x, 2))
# array([8, 9, 0, 1, 2, 3, 4, 5, 6, 7])
波形位移函数:
def time_shift(x, shift):
# shift:移动的长度
return np.roll(x, int(shift))
Augmentation = time_shift(wav_data, shift=fs//2)

六、波形拉伸
在不影响音高的情况下改变声音的速度 / 持续时间。这可以使用librosa的time_stretch函数来实现。
def time_stretch(x, rate):
# rate:拉伸的尺寸,
# rate > 1 加快速度
# rate 1 放慢速度
return librosa.effects.time_stretch(x, rate)
Augmentation = time_stretch(wav_data, rate=2)
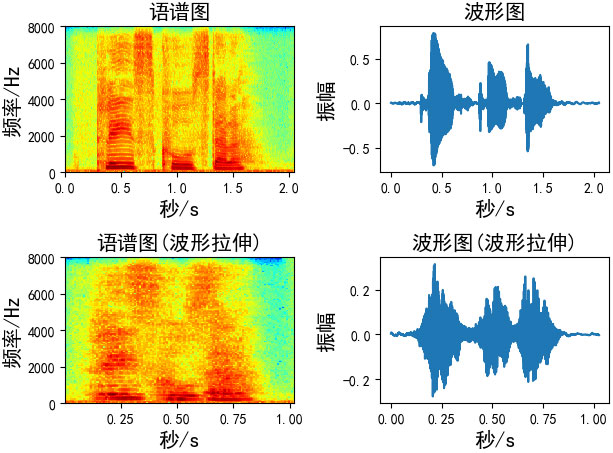
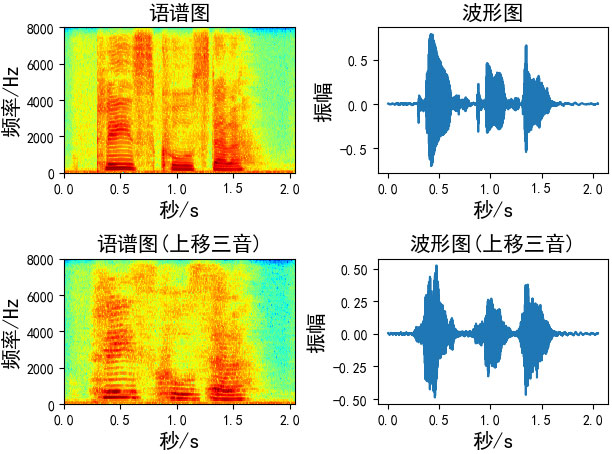
七、音高修正(Pitch Shifting)
音高修正只改变音高而不影响音速,我发现-5到5之间的步数更合适
def pitch_shifting(x, sr, n_steps, bins_per_octave=12):
# sr: 音频采样率
# n_steps: 要移动多少步
# bins_per_octave: 每个八度音阶(半音)多少步
return librosa.effects.pitch_shift(x, sr, n_steps, bins_per_octave=bins_per_octave)
# 向上移三音(如果bins_per_octave为12,则六步)
Augmentation = pitch_shifting(wav_data, sr=fs, n_steps=6, bins_per_octave=12)
# 向上移三音(如果bins_per_octave为24,则3步)
Augmentation = pitch_shifting(wav_data, sr=fs, n_steps=3, bins_per_octave=24)
# 向下移三音(如果bins_per_octave为12,则六步)
Augmentation = pitch_shifting(wav_data, sr=fs, n_steps=-6, bins_per_octave=12)
还有写没有跑通,但是总感觉有些价值的代码,记录在这里:
py-RIR-Generator(没跑通的原因是我是window系统)gpuRIR(这个我跑通了,但是需要较大的计算资源)去github找代码的时候,不一定要搜索“回声”,“混响”,也可以通过搜索"RIR"同样可以得到想要的结果
本文画图代码:
# Author:凌逆战
# -*- coding:utf-8 -*-
import matplotlib.pyplot as plt
import librosa
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示符号
y1, _ = librosa.load("./speech.wav", sr=16000)
y2, _ = librosa.load("./guitar_16k_reverb_ISM.wav", sr=16000)
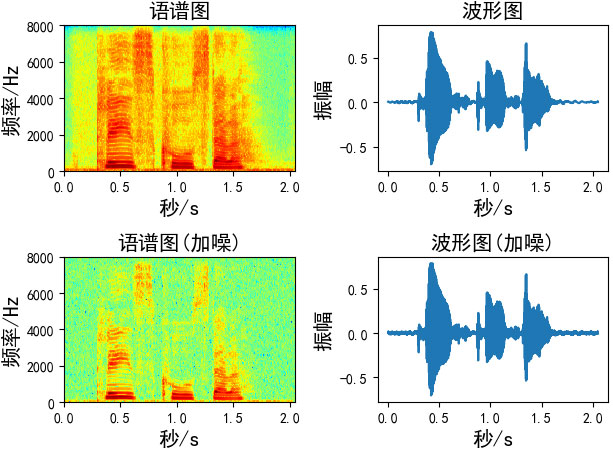
plt.subplot(2, 2, 1)
plt.specgram(y1, Fs=16000, scale_by_freq=True, sides='default', cmap="jet")
plt.title("语谱图", fontsize=13)
plt.xlabel('时间/s', fontsize=13)
plt.ylabel('频率/Hz', fontsize=13)
plt.subplot(2, 2, 2)
plt.plot(np.arange(len(y1)) / 16000, y1)
plt.title("波形图", fontsize=13)
plt.xlabel('时间/s', fontsize=13)
plt.ylabel('振幅', fontsize=13)
plt.subplot(2, 2, 3)
plt.specgram(y2, Fs=16000, scale_by_freq=True, sides='default', cmap="jet")
plt.title("语谱图(加混响)", fontsize=13)
plt.xlabel('时间/s', fontsize=13)
plt.ylabel('频率/Hz', fontsize=13)
plt.subplot(2, 2, 4)
plt.plot(np.arange(len(y2)) / 16000, y2)
plt.title("波形图(加混响)", fontsize=13)
plt.xlabel('时间/s', fontsize=13)
plt.ylabel('振幅', fontsize=13)
plt.tight_layout()
plt.show()
以上就是分析语音数据增强及python实现的详细内容,更多关于语音数据增强 python实现的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:- python3实现语音转文字(语音识别)和文字转语音(语音合成)
- python语音识别指南终极版(有这一篇足矣)
- 使用Python和百度语音识别生成视频字幕的实现
- 基于python实现语音录入识别代码实例
- Python谱减法语音降噪实例
- python实现智能语音天气预报
- Python(PyS60)实现简单语音整点报时
- python文字转语音实现过程解析
- 使用python实现语音文件的特征提取方法