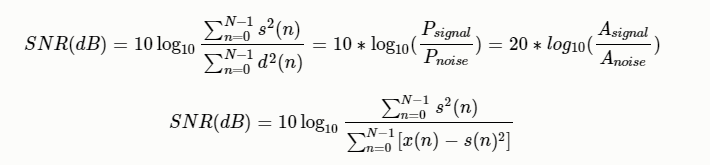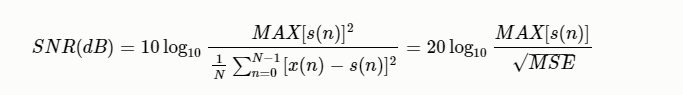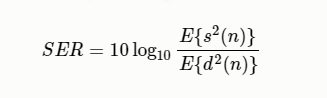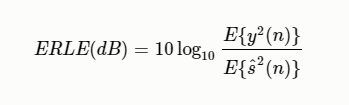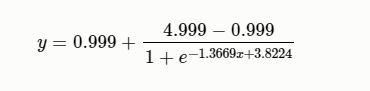语音信号处理一般都要进行主观评价实验和客观评价实验。
- 主观评价:邀请测听者对语音进行测听,给出主观意见得分
- 客观评价:根据算法来衡量语音质量
主观投票受多种因素影响,如个体受试者的偏好和实验的语境(其他条件)。一个好的客观质量度量应该与许多不同的主观实验有很高的相关性
信噪比(SNR)
有用信号功率与噪声功率的比(此处功率为平均功率),也等于幅度比的平方
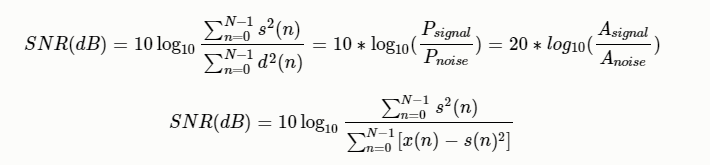
其中:$P_{signal}$为信号功率(平均功率或者实际功率);$P_{noise}$为噪声功率;$A_{signal}$为信号幅度;$A_{noise}$为噪声幅度值,功率等于幅度值的平方
MATLAB版本代码
# 信号与噪声长度应该一样
function snr=SNR_singlech(Signal,Noise)
P_signal = sum(Signal-mean(Signal)).^2; # 信号的能量
P_noise = sum(Noise-mean(Noise)).^2; # 噪声的能量
snr = 10 * log10(P_signal/P_noise)
tensorflow版本SNR
def tf_compute_snr(labels, logits):
# labels和logits都是三维数组 (batch_size, wav_data, 1)
signal = tf.reduce_mean(labels ** 2, axis=[1, 2])
noise = tf.reduce_mean((logits - labels) ** 2, axis=[1, 2])
noise = tf.reduce_mean((logits - labels) ** 2 + 1e-6, axis=[1, 2])
snr = 10 * tf.log(signal / noise) / tf.log(10.)
# snr = 10 * tf.log(signal / noise + 1e-8) / tf.log(10.)
snr = tf.reduce_mean(snr, axis=0)
return snr
def Volodymyr_snr(labels, logits):
# labels和logits都是三维数组 (batch_size, wav_data, 1)
noise = tf.sqrt(tf.reduce_mean((logits - labels) ** 2 + 1e-6, axis=[1, 2]))
signal = tf.sqrt(tf.reduce_mean(labels ** 2, axis=[1, 2]))
snr = 20 * tf.log(signal / noise + 1e-8) / tf.log(10.)
avg_snr = tf.reduce_mean(snr, axis=0)
return avg_snr
Volodymyr Kuleshov论文实现方法
批注:这里的1e-6和1e-8,目的是为了防止出现Nan值,如果没有这个需求可以去除
numpy版本代码
def numpy_SNR(labels, logits):
# origianl_waveform和target_waveform都是一维数组 (seq_len, )
# np.sum实际功率;np.mean平均功率,二者结果一样
signal = np.sum(labels ** 2)
noise = np.sum((labels - logits) ** 2)
snr = 10 * np.log10(signal / noise)
return snr
峰值信噪比(PSNR)
表示信号的最大瞬时功率和噪声功率的比值,最大瞬时功率为语音数据中最大值得平方。
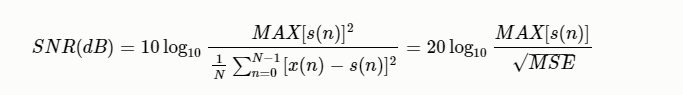
def psnr(label, logits):
MAX = np.max(label) ** 2 # 信号的最大平时功率
MSE = np.mean((label - logits) ** 2)
return np.log10(MAX / MSE)
分段信噪比(SegSNR)
由于语音信号是一种缓慢变化的短时平稳信号,因而在不同时间段上的信噪比也应不一样。为了改善上面的问题,可以采用分段信噪比。分段信噪比即是先对语音进行分帧,然后对每一帧语音求信噪比,最好求均值。
MATLAB版本的代码
function [segSNR] = Evaluation(clean_speech,enhanced)
N = 25*16000/1000; %length of the segment in terms of samples
M = fix(size(clean_speech,1)/N); %number of segments
segSNR = zeros(size(enhanced));
for i = 1:size(enhanced,1)
for m = 0:M-1
sum1 =0;
sum2 =0;
for n = m*N +1 : m*N+N
sum1 = sum1 +clean_speech(n)^2;
sum2 = sum2 +(enhanced{i}(n) - clean_speech(n))^2;
end
r = 10*log10(sum1/sum2);
if r>55
r = 55;
elseif r -10
r = -10;
end
segSNR(i) = segSNR(i) +r;
end
segSNR(i) = segSNR(i)/M;
end
python代码
def SegSNR(ref_wav, in_wav, windowsize, shift):
if len(ref_wav) == len(in_wav):
pass
else:
print('音频的长度不相等!')
minlenth = min(len(ref_wav), len(in_wav))
ref_wav = ref_wav[: minlenth]
in_wav = in_wav[: minlenth]
# 每帧语音中有重叠部分,除了重叠部分都是帧移,overlap=windowsize-shift
# num_frame = (len(ref_wav)-overlap) // shift
# = (len(ref_wav)-windowsize+shift) // shift
num_frame = (len(ref_wav) - windowsize + shift) // shift # 计算帧的数量
SegSNR = np.zeros(num_frame)
# 计算每一帧的信噪比
for i in range(num_frame):
noise_frame_energy = np.sum(ref_wav[i * shift: i * shift + windowsize] ** 2) # 每一帧噪声的功率
speech_frame_energy = np.sum(in_wav[i * shift: i * shift + windowsize] ** 2) # 每一帧信号的功率
SegSNR[i] = np.log10(speech_frame_energy / noise_frame_energy)
return 10 * np.mean(SegSNR)
信号回声比 (Signal to echo ratio, SER)
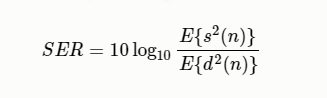
其中E是统计 期望操作,$s(n)$是近端语音,$d(n)$是远端回声
def SER(near_speech, far_echo):
"""signal to echo ratio, 信号回声比
:param near_speech: 近端语音
:param far_echo: 远端回声
"""
return 10*np.log10(np.mean(near_speech**2)/np.mean(far_echo**2))
回声损失增强 (Echo Return Loss Enhancement, ERLE)
回波损失增强度量(ERLE)通常用于评估系统在没有近端信号的单通话情况下 的回声减少。ERLE的定义是
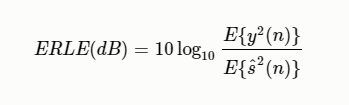
其中E是统计 期望操作,$y(n)$是麦克风信号,$\hat{s}(n)$是估计的近端语音信号。
def compute_ERLE(mic_wav, predict_near_end_wav):
"""
:param mic_wav: 麦克风信号(y) = 近端语音(s) + 远端语音回声(s) + 噪声(v)
:param predict_near_end_wav: 估计的近端语音信号 \hat{s}
麦克风信号
"""
mic_mear = np.mean(mic_wav**2)
predict_near_end_wav = np.mean(predict_near_end_wav**2)
ERLE = 10 * np.log10(mic_mear/predict_near_end_wav)
return ERLE
为了评估系统在双讲情况下的性能,通常采用PESQ(语音质量感知评价)或STOI (短时语音可懂度),他是通过将估计的近端语音和仅在双讲通话期间真实的近端语音进行比较得到的。PESQ评分范围为-0.5 ~ 4.5,分数越高质量越好。STOI评分范围为0~1,分数越高越好。
对数拟然对比度 (log Likelihood Ratio Measure)
坂仓距离测度是通过语音信号的线性预测分析来实现的。ISD基于两组线性预测参数(分别从原纯净语音和处理过的语音的同步帧得到)之间的差异。LLR可以看成一种坂仓距离(Itakura Distance,IS)但是IS距离需要考虑模型增益。而LLR不需要考虑模型争议引起的幅度位移,更重视整体谱包络的相似度。
语音质量感知评估 (Perceptual Evaluation of Speech Quality, PESQ)
引言:我先做个简要介绍,再讲使用。使用之前建议还是详细了解一下,不要用错了,导致论文被拒,或者做了伪研究,以下内容是我挑重点摘自ITU-T P862建议书,比较权威,重要的地方我会加粗。想要进一步了解的自行去下载原文。
PESQ是由国际电信联盟(International Telecommunication Union,ITU) 2001年提供的ITU-T P862建议书:语音质量的感知评估(PESQ):窄带电话网络和语音编解码器的端到端语音质量评估的客观方法,并提供了ANSI-C语言实现代码。真实系统可能包括滤波和可变延迟,以及由于信道误差和低比特率编解码器引起的失真。国际电联电信政策861中描述的PSQM方法仅被推荐用于评估语音编解码器,不能适当考虑滤波、可变延迟和短时局部失真。PESQ通过传递函数均衡、时间校准和一种新的时间平均失真算法来解决这些影响。PESQ的验证包括许多实验,这些实验专门测试了它在滤波、可变延迟、编码失真和信道误差等因素组合下的性能。
建议将PESQ用于3.1kHz(窄带)手机电话和窄带语音编解码器的语音质量评估。PESQ是属于客观评价,和主观分数之间的相关性约为0.935,但PESQ算法不能用来代替主观测试。
PESQ算法没有提供传输质量的综合评估。它只测量单向语音失真和噪声对语音质量的影响。响度损失、延迟、侧音、回声和其他与双向互动相关的损伤(如中央削波器)的影响不会反映在PESQ分数中。因此,有可能有很高的PESQ分数,但整体连接质量很差。
PESQ的感知模型用于计算原始信号$X(t)$与退化信号$Y(t)$之间的距离(PESQ分数),退化信号$Y(t)$是$X(t)$通过通信系统的结果。PESQ的输出是对受试者在主观听力测试中给予$Y(t)$的感知质量的预测。取值在-0.5到4.5的范围内,得分越高表示语音质量越好,尽管在大多数情况下输出范围在1.0到4.5之间。

ITU提供了C语言代码,下载请点击这里,但是在使用之前我们需要先编译C脚本,生成可执行文件exe
编译方式为:在命令行进入下载好的文件
- cd\Software\source
- gcc -o PESQ *.c
经过编译,会在当前文件夹生成一个pesq.exe的可执行文件
使用方式为:
- 命令行进入pesq.exe所在的文件夹
- 执行命令:pesq 采样率 "原始文件路径名" "退化文件路径名”,采样率必须选择+8000(窄带)或+16000(宽带),
- 回车
- 等待结果即可,值越大,质量越好。
例如:pesq +16000 raw.wav processed.wav
python代码实现
参考地址:https://github.com/ludlows/python-pesq
首先我们需要安装pesq库:pip install pesq
from scipy.io import wavfile
from pesq import pesq
rate, ref = wavfile.read("./audio/speech.wav")
rate, deg = wavfile.read("./audio/speech_bab_0dB.wav")
print(pesq(rate, ref, deg, 'wb'))
print(pesq(rate, ref, deg, 'nb'))
该python库返回的是MOS-LQO,属于pesq的映射,现在用的更多的也是MOS-LQO。如果你硬是想要PESQ得分,你可以自行逆变换回去,公式见下一节
MOS-LQO
MOS-LQO (Mean Opinion Score – Listening Quality Objective),使用客观测量技术评估主观听力质量)与之相对的还有MOS-LQS(Mean Opinion Score – Listening Quality Subjective),使用样本的主观评分直接衡量听力质量,就是主观评价了。
功能:将P.862原始结果分数转换为MOS-LQO的映射,P862.1:用于将P.862原始结果分数转换为MOS-LQO的映射函数.pdf
ITU-TP.862建议书提供的原始分数在-0.5到4.5之间。希望从PESQ (P.862)得分中转换为MOS-LQO (P.862.1)分数,从而可以与MOS进行线性比较。该建议书介绍了从原始P.862得分到MOS-LQO(P.800.1)的映射函数及其性能。映射函数已在代表不同应用程序和语言的大量主观数据上进行了优化,所呈现的性能优于原始的PESQ(P862),取值在[1, 4.5]之间,连续的。公式为:
$$公式1:y=0.999+\frac{4.999-0.999}{1+e^{-1.4945x+4.6607}}$$

python实现
def pesq2mos(pesq):
""" 将PESQ值[-0.5, 4.5]映射到MOS-LQO得分[1, 4.5]上,映射函数来源于:P.862.1 """
return 0.999 + (4.999 - 0.999) / (1 + np.exp(-1.4945 * pesq + 4.6607))
MATLAB官方实现请参见:
公式2给出了从MOS-LQO分数到PESQ分数的转换的反映射函数

python实现
def mos2pesq(mos):
""" 将MOS-LQO得分[1, 4.5]映射到PESQ值[-0.5, 4.5]上,映射函数来源于:P.862.1"""
inlog = (4.999 - mos) / (mos - 0.999)
return (4.6607 - np.log(inlog)) / 1.4945
需要注意的是,所提供的函数有一些实际限制:
- 本文提供的映射函数对源自所有类型应用程序的数据库进行了优化。仅针对特定应用程序或语言进行优化的其他映射函数可能在该特定应用程序或语言上比提供的函数执行得更好。
- 虽然训练数据库包含分数较低的MOS区域中的样本比例很大,但是在原始P.862分数0.5到1的范围内缺少样本。在此范围内,映射的P.862函数进行插值,因此确定了预测误差Ep和平均残差Em
PESQ-WB
2007年11.13国际电联公布了PESQ的宽带版本(ITU-T P862.2,PESQ-WB),P.862建议书的宽带扩展,用于评估宽带电话网络和语音编解码器,主要用于宽带音频系统 (50-7000 Hz),尽管它也可以应用于带宽较窄的系统。例如听众使用宽带耳机的语音编解码器。相比之下,ITU-T P.862建议书假设使用标准的IRS型窄带电话手机,在300 Hz以下和3100 Hz以上会强烈衰减。
使用范围
- 不建议将PESQ-WB用在信号插入点和信号捕获点之间包含噪声抑制算法的系统。 另外,应使用干净的语音样本,因为嘈杂的语音样本,即那些信噪比较差的语音样本,可能会导致预测错误。 用户还应注意,宽带语音主观实验中不同失真类别的相对排名可能会随语言种类而略有变化。 特别要注意的是,宽带扩展可能会高估ITU-T Rec.3建议书的MOS分数。
- 当使用PESQ-WB来比较可能对音频信号进行频带限制的系统的性能时,建议使用一个宽带(50-7000 Hz音频带宽)版本的信号作为所有参考信号。被限制带宽的测试系统会导致语音性能下降,降低输出分数。这种限制可能会降低信号的预测精度。不建议存在信号退化的严重限制,即小于传统电话带宽(300- 3400hz) 。
- PESQ-WB是评估宽带语音条件的主观实验的背景下预测主观意见,即音频带宽从50赫兹扩展到7000赫兹的信号。这意味着,由于不同的实验环境,无法直接比较宽带扩展产生的分数和基线[ITU-T P862]或[ITU-T P862.1]产生的分数。
基本的P.862模型提供的原始分数在–0.5到4.5之间。 [ITU-T P.862]的PESQ-WB包括一个映射函数,输出的也是映射值,该函数允许与主观评价的MOS得分进行线性比较,这些主观实验包括音频带宽为50-7000 Hz的宽带语音条件。 这意味着由于实验环境的不同,无法直接比较PESQ-WB产生的分数和基线[ITU-T P.862]或[ITU-T P.862.1]产生的分数。PESQ-WB中使用的输出映射函数定义如下:
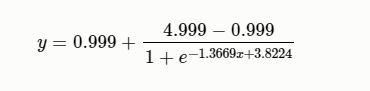
其中$x$是原模型输出。
[ITU-T P.862]的附件A中给出了了PESQ-WB的宽带扩展的ANSI-C参考实现。
感知客观语音质量评估 (POLQA)
POLQA度量方法授权给了epticom公司,只有该公司授权的机构才能使用,我总结在这就是让大家了解一下,反正我们都用不了,哈哈
ITU P.863建议书提供了一种客观评价方法:感知客观语音质量评估 (Perceptual objective listening quality prediction, P.OLQA),ITU-T P.863建议书支持两种操作模式,一种用于窄带 (NB, 300Hz-3.4kHz),一种用于全带 (FB, 20Hz-20kHz)。
可以应用到全频带语音编解码器(例如,OPUS,增强语音服务(EVS))。比较参考信号X(t)和退化信号Y(t),其中Y(t)是通过通信系统传递X(t)的结果,人类听觉系统中音频信号的心理物理表征,
ITU-T P.863算法消除了参考信号中的低水平噪声,同时对退化输出信号中的噪声也进行了部分抑制。
一个好的客观质量测量应该与多个不同的主观实验有很高的相关性。在实践中,使用ITU-T P.863算法,回归映射通常几乎是线性的,在日常实践中,不需要对客观分数进行特殊映射,因为ITU-T P.863分数已经映射到MOS尺度,反映了大量单独数据集的平均值。
POLQA结果主要是模型平均意见得分(MOS),涵盖从1(差)到5(优秀)的范围。在全频带模式下得分为MOS-LQO 4.80,在窄带模式下得分为MOS-LQO 4.5。这反映了一个事实,即不是所有的主观测试参与者都会给最高的评级,即使是不降级的参考。

对数谱距离(LSD)
对数谱距离Log Spectral Distance,LSD是两个频谱之间的距离度量。也称为“对数谱失真”

式中,$l$和$m$分别为频率索引和帧索引,$M$为语音帧数,$L$为频点数,$\hat{S}(l, m)$和$S(l, m)$分别为估计音频和宽带音频经过短时短时傅里叶变换后的频谱。
numpy版本
# 方法一
def numpy_LSD(labels, logits):
""" labels 和 logits 是一维数据 (seq_len,)"""
labels_spectrogram = librosa.stft(labels, n_fft=2048) # (1 + n_fft/2, n_frames)
logits_spectrogram = librosa.stft(logits, n_fft=2048) # (1 + n_fft/2, n_frames)
labels_log = np.log10(np.abs(labels_spectrogram) ** 2)
logits_log = np.log10(np.abs(logits_spectrogram) ** 2)
# 先处理频率维度
lsd = np.mean(np.sqrt(np.mean((labels_log - logits_log) ** 2, axis=0)))
return lsd
# 方法二
def get_power(x):
S = librosa.stft(x, n_fft=2048) # (1 + n_fft/2, n_frames)
S = np.log10(np.abs(S) ** 2)
return S
def compute_log_distortion(labels, logits):
"""labels和logits数据维度为 (batch_size, seq_len, 1)"""
avg_lsd = 0
batch_size = labels.shape[0]
for i in range(batch_size):
S1 = get_power(labels[i].flatten())
S2 = get_power(logits[i].flatten())
# 先处理频率轴,后处理时间轴
lsd = np.mean(np.sqrt(np.mean((S1 - S2) ** 2, axis=0)), axis=0)
avg_lsd += lsd
return avg_lsd / batch_size
tensorflow版本
def get_power(x):
x = tf.squeeze(x, axis=2) # 去掉位置索引为2维数为1的维度 (batch_size, input_size)
S = tf.signal.stft(x, frame_length=2048, frame_step=512, fft_length=2048,
window_fn=tf.signal.hann_window)
# [..., frames, fft_unique_bins]
S = tf.log(tf.abs(S) ** 2) / tf.log(10.)
# S = tf.log(tf.abs(S) ** 2 + 9.677e-9) / tf.log(10.)
return S
def tf_compute_log_distortion(labels, logits):
"""labels和logits都是三维数组 (batch_size, input_size, 1)"""
S1 = get_power(labels) # [..., frames, fft_unique_bins]
S2 = get_power(logits) # [..., frames, fft_unique_bins]
# 先处理频率维度,后处理时间维度
lsd = tf.reduce_mean(tf.sqrt(tf.reduce_mean((S1 - S2) ** 2, axis=2)), axis=1)
lsd = tf.reduce_mean(lsd, axis=0)
return lsd
但如果想要numpy版本的值和tensorflow版本的值一样,可以使用下面的代码
# numpy版本一:处理一个batch,(batch, seq_len, 1)
def numpy_LSD(labels, logits):
""" labels 和 logits 是一维数据"""
labels_spectrogram = librosa.stft(labels, n_fft=2048, hop_length=512, win_length=2048,
window="hann", center=False) # (1 + n_fft/2, n_frames)
logits_spectrogram = librosa.stft(logits, n_fft=2048, hop_length=512, win_length=2048,
window="hann", center=False) # (1 + n_fft/2, n_frames)
labels_log = np.log10(np.abs(labels_spectrogram) ** 2 + 1e-8)
logits_log = np.log10(np.abs(logits_spectrogram) ** 2 + 1e-8)
original_target_squared = (labels_log - logits_log) ** 2
lsd = np.mean(np.sqrt(np.mean(original_target_squared, axis=0)))
return lsd
# numpy版本二:处理一个batch,(batch, seq_len, 1)
def get_power1(x):
S = librosa.stft(x, n_fft=2048, hop_length=512, win_length=2048,
window="hann", center=False) # (1 + n_fft/2, n_frames)
S = np.log10(np.abs(S) ** 2 + 1e-8)
return S
def compute_log_distortion(labels, logits):
avg_lsd = 0
batch_size = labels.shape[0]
for i in range(batch_size):
S1 = get_power1(labels[i].flatten())
S2 = get_power1(logits[i].flatten())
# 先处理频率轴,后处理时间轴
lsd = np.mean(np.sqrt(np.mean((S1 - S2) ** 2, axis=0)), axis=0)
avg_lsd += lsd
return avg_lsd / batch_size
# tensorflow版本
def get_power(x):
x = tf.squeeze(x, axis=2) # 去掉位置索引为2维数为1的维度 (batch_size, input_size)
S = tf.signal.stft(x, frame_length=2048, frame_step=512, fft_length=2048,
window_fn=tf.signal.hann_window)
# [..., frames, fft_unique_bins]
S = tf.log(tf.abs(S) ** 2 + 9.677e-9) / tf.log(10.)
return S
def tf_compute_log_distortion(labels, logits):
# labels和logits都是三维数组 (batch_size, input_size, 1)
S1 = get_power(labels) # [..., frames, fft_unique_bins]
S2 = get_power(logits) # [..., frames, fft_unique_bins]
# 先处理频率维度,后处理时间维度
lsd = tf.reduce_mean(tf.sqrt(tf.reduce_mean((S1 - S2) ** 2, axis=2)), axis=1)
lsd = tf.reduce_mean(lsd, axis=0)
return lsd
批注:librosa.stft中center设为False,和np.log10中加1e-8,目的是为了最终的值和tensorflow版本的lsd值相近,如果没有这个需求可以去除。这里tf.log中加9.677e-9是为了和numpy中的值相近,如果没有这个需求可以去除
短时客观可懂度(STOI)
下载一个 pystoi 库:pip install pystoi
STOI 反映人类的听觉感知系统对语音可懂度的客观评价,STOI 值介于0~1 之间,值越大代表语音可懂度越高,越清晰。
from pystoi import stoi
stoi_score = stoi(label, logits, fs_sig=16000)
加权谱倾斜测度(WSS)
WSS值越小说明扭曲越少,越小越好,范围
参考
【CSDN文章】PESQ语音质量测试
视频质量度量指标
度量方法仓库
【github代码,内涵多种度量方法】pysepm
【python库】python-pesq
【python库】pystoi
speechmetrics
Voice quality metrics
以上就是python实现语音常用度量方法的详细内容,更多关于python语音度量方法的资料请关注脚本之家其它相关文章!
您可能感兴趣的文章:- python3实现语音转文字(语音识别)和文字转语音(语音合成)
- python语音识别指南终极版(有这一篇足矣)
- 使用Python和百度语音识别生成视频字幕的实现
- python 利用pyttsx3文字转语音过程详解
- Python将文字转成语音并读出来的实例详解