在算face_track_id map有感:
data={'state':[1,1,2,2,1,2,2,2],'pop':['a','b','c','d','b','c','d','d']}
frame=pd.DataFrame(data)
frame
frame.shape $ (8,2)
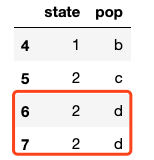
# 说明duplicated()是对整行进行查重,return 重复了的数据,且只现实n-1条重复的数据(n是重复的次数) frame[frame.duplicated() == True]
一开始还很疑惑,明明(1,b)只出现了1次,哪里duplicate了。其实,人家return的结果是去掉已经出现过一次的行数据了。所以看起来有点confuse,感觉(1,b)并没有重复,但其实人家的函数很简洁呢,返回了重复值而且不冗余。
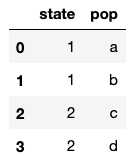
# 说明drop_duplicates()函数是将所有重复的数据都去掉了,且默认保留重复数据的第一条。 # 比如(2,d)出现了3次,在duplicated()中显示了2次,在drop_dupicates()后保留了一个 frame.drop_duplicates().shape $ (4,2)
# 留下了完全唯一的数据行 frame.drop_duplicates()
补充:python的pandas重复值处理(duplicated()和drop_duplicates())
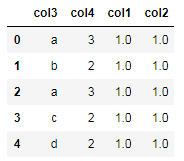
import numpy as np import pandas as pd #生成重复数据 df=pd.DataFrame(np.ones([5,2]),columns=['col1','col2']) df['col3']=['a','b','a','c','d'] df['col4']=[3,2,3,2,2] df=df.reindex(columns=['col3','col4','col1','col2']) #将新增的一列排在第一列 df
输出:
#判断重复数据 isDplicated=df.duplicated() #判断重复数据记录 isDplicated
输出:

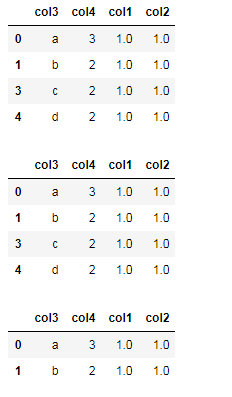
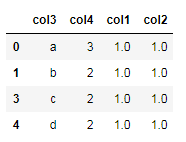
#删除重复值 new_df1=df.drop_duplicates() #删除数据记录中所有列值相同的记录 new_df2=df.drop_duplicates(['col3']) #删除数据记录中col3列值相同的记录 new_df3=df.drop_duplicates(['col4']) #删除数据记录中col4列值相同的记录 new_df4=df.drop_duplicates(['col3','col4']) #删除数据记录中(col3和col4)列值相同的记录 new_df1 new_df2 new_df3 new_df4
输出:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。




