数据处理过程中,经常会遇到数据有缺失值的情况,本文介绍如何用Pandas处理数据中的缺失值。
对数据而言,缺失值分为两种,一种是Pandas中的空值,另一种是自定义的缺失值。
1. Pandas中的空值有三个:np.nan (Not a Number) 、 None 和 pd.NaT(时间格式的空值,注意大小写不能错),这三个值可以用Pandas中的函数isnull(),notnull(),isna()进行判断。
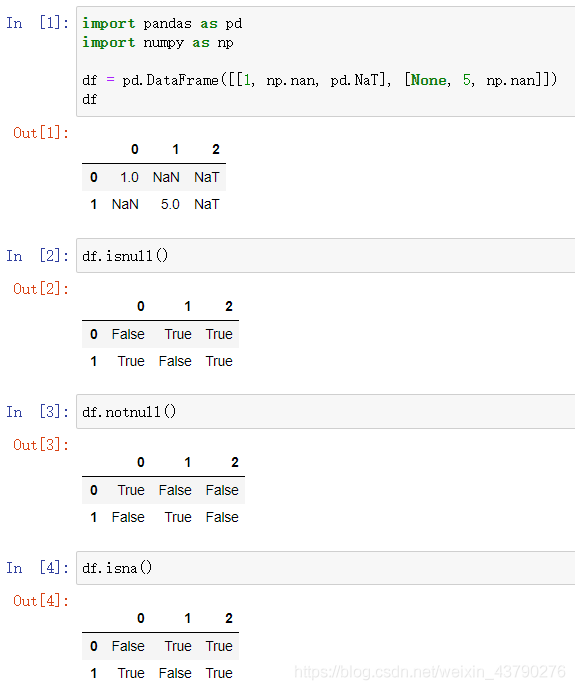
isnull()和notnull()的结果互为取反,isnull()和isna()的结果一样。对于这三个函数,只需要用其中一个就可以识别出数据中是否有空值。如果数据量较大,再配合numpy中的any()和all()函数就行了。
需要特别注意两点:
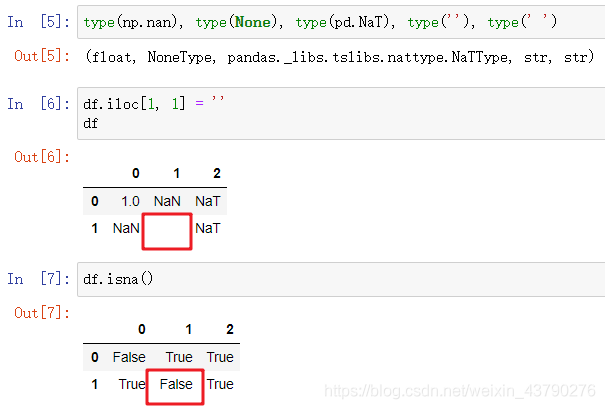
从Python解释器来看,np.nan的类型是float,None的类型是NoneType,两者在Pandas中都显示为NaN,pd.NaT的类型是Pandas中的NaTType,显示为NaT。而不管是空字符串还是空格,其数据类型都是字符串,Pandas判断的结果不是空值。
2. 自定义缺失值有很多不同的形式,如上面刚说的空字符串和空格(当然,一般不用这两个,因为看起来不够直观)。
在获取数据时,可能会有一些数据无法得到,也可能数据本身就没有,造成了缺失值。对于这些缺失值,在获取数据时通常会用一些符号之类的数据来代替,如问号?,斜杠/,字母NA等。
如果处理的数据是自己获取的,那自己知道缺失值是怎么定义的,如果数据是其他人提供的,一般会同时提供数据的说明文档,说明文档中会注明缺失值的定义方式。
对于自定义缺失值,不能用isnull()等三个函数来判断,不过可以用isin()函数来判断。找到这些值后,将其替换成np.nan,数据就只有空值一种缺失值了。
此外,在数据处理的过程中,也可能产生缺失值,如除0计算,数字与空值计算等。
1. 自定义缺失值的判断和替换
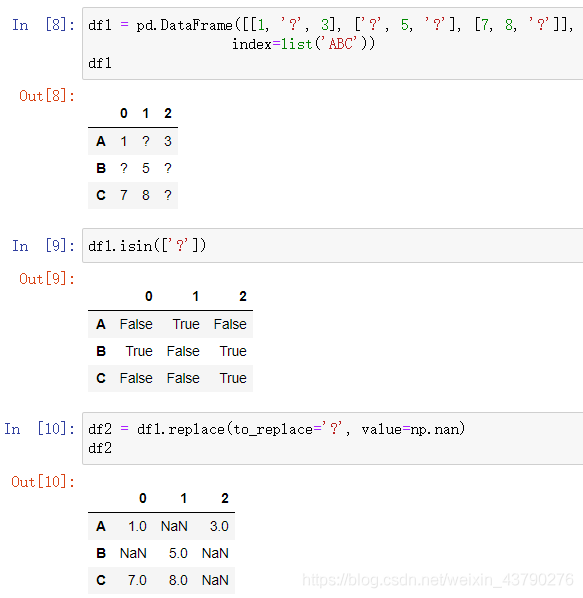
isin(values): 判断Series或DataFrame中是否包含某些值,可以传入一个可迭代对象、Series、DataFrame或字典。在我们判断某个自定义的缺失值是否存在于数据中时,用列表的方式传入就可以了。
replace(to_replace=None, value=None): 替换Series或DataFrame中的指定值,一般传入两个参数,to_replace为被替换的值,value为替换后的值。to_replace和value不仅支持Python中的整型、字符串、列表、字典等,还支持正则表达式。
使用replace()时,默认返回原数据的一个副本,replace()中的inplace参数默认为False,将inplace参数修改为True,则会修改数据本身。其他参数这里就不展开了,有需要可以自己添加。
其实replace()函数已经可以用于缺失值的填充处理了,直接一步到位,而不用先替换成空值再处理。当然,先替换成空值,可以与空值一起处理。
2. 空值判断
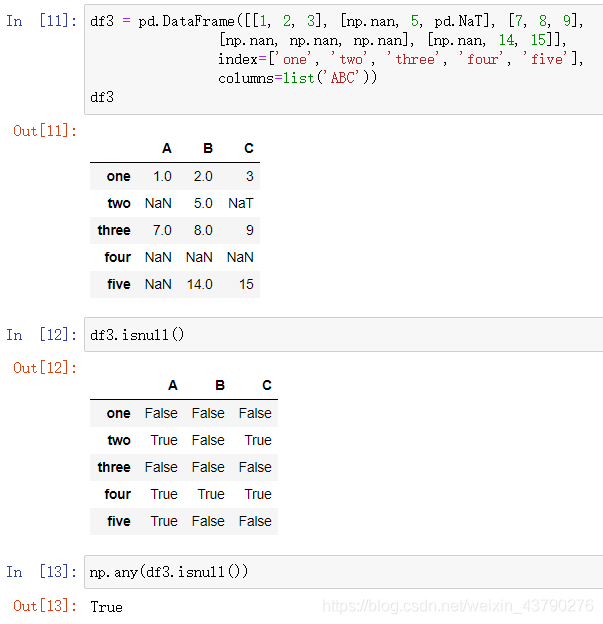
isnull(): 判断Series或DataFrame中是否包含空值,与isna()结果相同,与notnull()结果相反。返回结果是一个与原数据形状相同的Series或DataFrame。
如果数据很多,我们不可能肉眼观察返回结果中的布尔值,所以需要借助numpy中的any()函数或all()函数,进一步对结果进行判断。
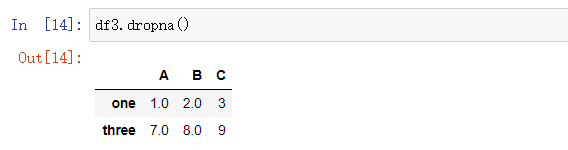
dropna(axis=0, how="any", thresh=None, subset=None, inplace=False): 删除Series或DataFrame中的空值。
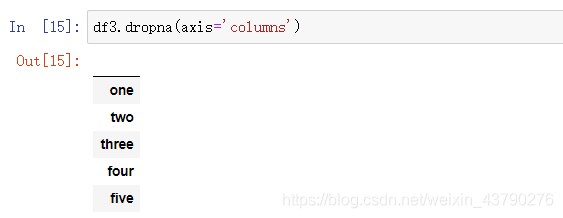
axis: axis参数默认为0('index'),按行删除,即删除有空值的行。将axis参数修改为1或‘columns',则按列删除,即删除有空值的列。在实际的应用中,一般不会按列删除,例如数据中的一列表示年龄,不能因为年龄有缺失值而删除所有年龄数据。
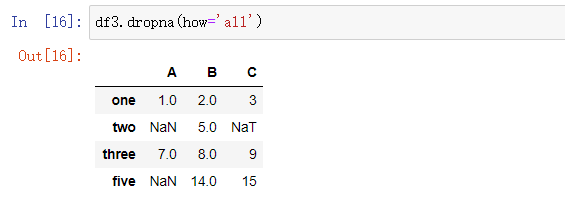
how: how参数默认为any,只要一行(或列)数据中有空值就会删除该行(或列)。将how参数修改为all,则只有一行(或列)数据中全部都是空值才会删除该行(或列)。
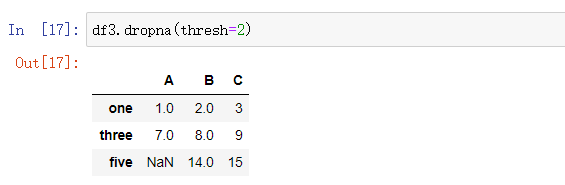
thresh: 表示删除空值的界限,传入一个整数。如果一行(或列)数据中少于thresh个非空值(non-NA values),则删除。也就是说,一行(或列)数据中至少要有thresh个非空值,否则删除。

subset: 删除空值时,只判断subset指定的列(或行)的子集,其他列(或行)中的空值忽略,不处理。当按行进行删除时,subset设置成列的子集,反之。
inplace: 默认为False,返回原数据的一个副本。将inplace参数修改为True,则会修改数据本身。
删除缺失值,必然会导致数据量的减少,如果缺失值占数据的比例较大,比如超过了数据的10%(具体标准根据项目来定),删除数据对数据分析的结果会有很大的影响,不合理。
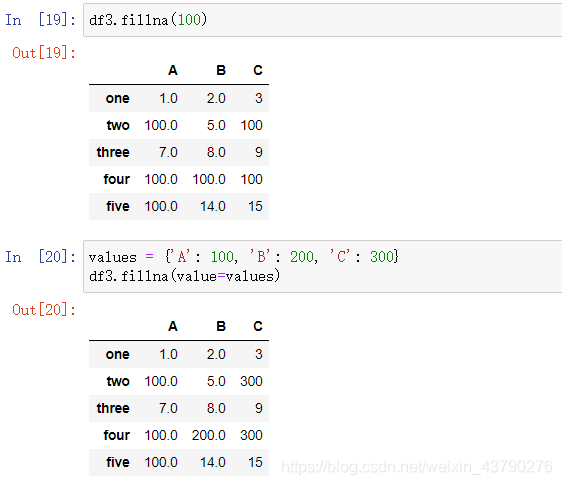
fillna(value=None, method=None, axis=None, inplace=False, limit=None): 填充Series或DataFrame中的空值。
value: 表示填充的值,可以是一个指定值,也可以是字典, Series或DataFrame。
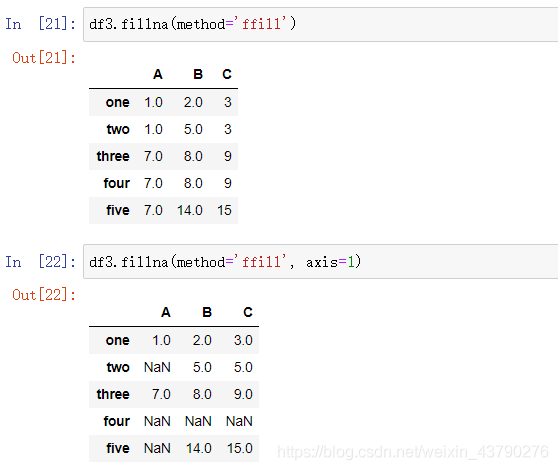
method: 填充的方式,默认为None。有 ffill,pad,bfill,backfill 四种填充方式可以使用,ffill 和 pad 表示用缺失值的前一个值填充,如果axis=0,则用空值上一行的值填充,如果axis=1,则用空值左边的值填充。假如空值在第一行或第一列,以及空值前面的值全都是空值,则无法获取到可用的填充值,填充后依然保持空值。bfill 和 backfill 表示用缺失值的后一个值填充,axis的用法以及找不到填充值的情况同 ffill 和 pad 。
注意:当指定填充方式method时,不能同时指定填充值value,否则报错。
axis: 通常配合method参数使用,axis=0表示按行,axis=1表示按列。
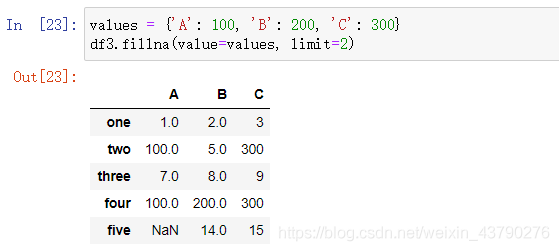
limit: 表示填充执行的次数。如果是按行填充,则填充一行表示执行一次,按列同理。
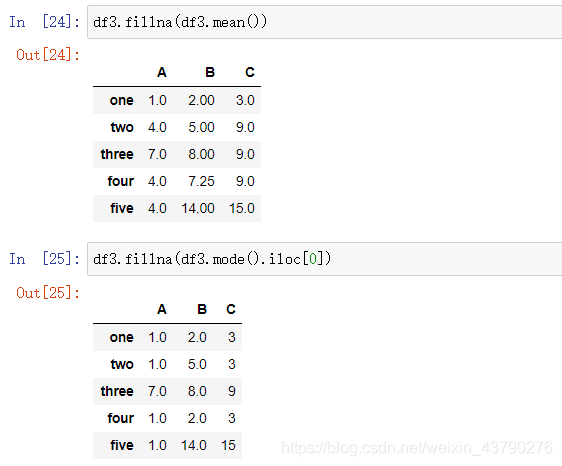
在缺失值填充时,填充值是自定义的,对于数值型数据,最常用的两种填充值是用该列的均值和众数。DataFrame的众数也是一个DataFrame数据,众数可能有多个(极限情况下,当数据中没有重复值时,众数就是原DataFrame本身),所以用mode()函数求众数时取第一行用于填充就行了。
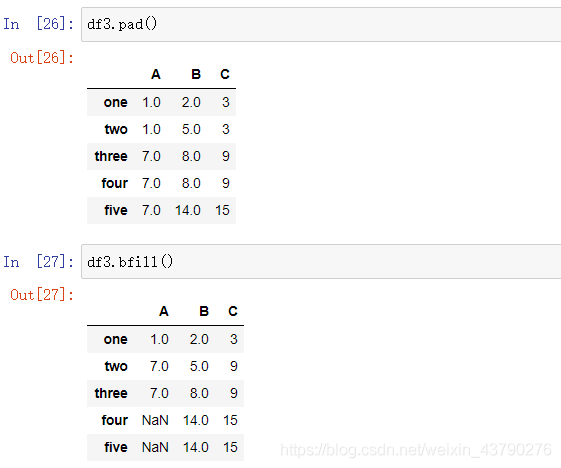
除了可以在fillna()函数中传入method参数指定填充方式外,Pandas中也实现了不同填充方式的函数,可以直接调用。
pad(axis=0, inplace=False, limit=None): 用缺失值的前一个值填充。
ffill(): 同pad()。
bfill(): 用缺失值的后一个值填充。
backfill(): 同bfill()。
在进行数据填充时,可能填充之后还有空值,如用ffill 和 pad填充时,数据第一行就是空值。对于这种情况,需要在填充前人工进行判断,避免选择不适合的填充方式,并在填充完成后,再检查一次数据中是否还有空值。
到此这篇关于Python Pandas知识点之缺失值处理的文章就介绍到这了,更多相关Pandas缺失值处理内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!




