1. Single array iteration
>>> a = np.arange(6).reshape(2,3)
>>> for x in np.nditer(a):
... print x,
...
0 1 2 3 4 5
也即默认是行序优先(row-major order,或者说是 C-order),这样迭代遍历的目的在于,实现和内存分布格局的一致性,以提升访问的便捷性;
>>> for x in np.nditer(a.T):
... print x,
...
0 1 2 3 4 5
>>> for x in np.nditer(a.T.copy(order='C')):
... print x,
...
0 3 1 4 2 5
也即对 a 和 a.T 的遍历执行的是同意顺序,也即是它们在内存中的实际存储顺序。
2. 控制遍历顺序
for x in np.nditer(a, order='F'):Fortran order,也即是列序优先;
for x in np.nditer(a.T, order='C'):C order,也即是行序优先;
3. 修改数组中元素的值
默认情况下,nditer将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 read-write 或者 write-only的模式。
>>> a
array([[0, 1, 2],
[3, 4, 5]])
>>> for x in np.nditer(a, op_flags=['readwrite']):
... x[...] = 2 * x
...
>>> a
array([[ 0, 2, 4],
[ 6, 8, 10]])
4. 使用外部循环
将一维的最内层的循环转移到外部循环迭代器,使得 numpy 的矢量化操作在处理更大规模数据时变得更有效率。
>>> a = np.arange(6).reshape(2,3)
>>> for x in np.nditer(a, flags=['external_loop']):
... print x,
...
[0 1 2 3 4 5]
>>>
>>> for x in np.nditer(a, flags=['external_loop'], order='F'):
... print x,
...
[0 3] [1 4] [2 5]
5. 追踪单个索引或多重索引(multi-index)
>>> a = np.arange(6).reshape(2,3)
>>> a
array([[0, 1, 2],
[3, 4, 5]])
>>> it = np.nditer(a, flags=['f_index'])
>>> while not it.finished:
... print "%d %d>" % (it[0], it.index),
... it.iternext()
...
0 0> 1 2> 2 4> 3 1> 4 3> 5 5>
# 索引的编号,以列序优先
>>> it = np.nditer(a, flags=['multi_index'])
>>> while not it.finished:
... print "%d %s>" % (it[0], it.multi_index),
... it.iternext()
...
0 (0, 0)> 1 (0, 1)> 2 (0, 2)> 3 (1, 0)> 4 (1, 1)> 5 (1, 2)>
补充:详解 Numpy.ndarray
向量、矩阵 多维数组是数值计算中必不可少的工具;通过对数组数据进行批量处理,避免了对数组元素显式地进行循环操作,这样做的结果是可以得到简洁、更易维护的代码,并且可以使用更底层的库来实现数组操作。因此,向量化计算相比按顺序逐元素进行计算要快得多。
在 Python科学计算环境中,Numpy 库提供了用于处理数组的高效数据结构,且Numpy的核心是使用C语言实现的,提供了很多处理和处理数组的函数。
NumPy支持比Python更多种类的数字类型,有5种基本数字类型:
布尔值(bool)
整数(int)
无符号整数(uint)
浮点(float)
复数(complex)
Numpy库的核心是表示 同质的多维数据 —— 每个元素占用相同大小的内存块, 并且所有块都以完全相同的方式解释。 如何解释数组中的每个元素由单独的数据类型对象指定, 其中一个对象与每个数组相关联。除了基本类型(整数,浮点数 等 )之外, 数据类型对象还可以表示数据结构。

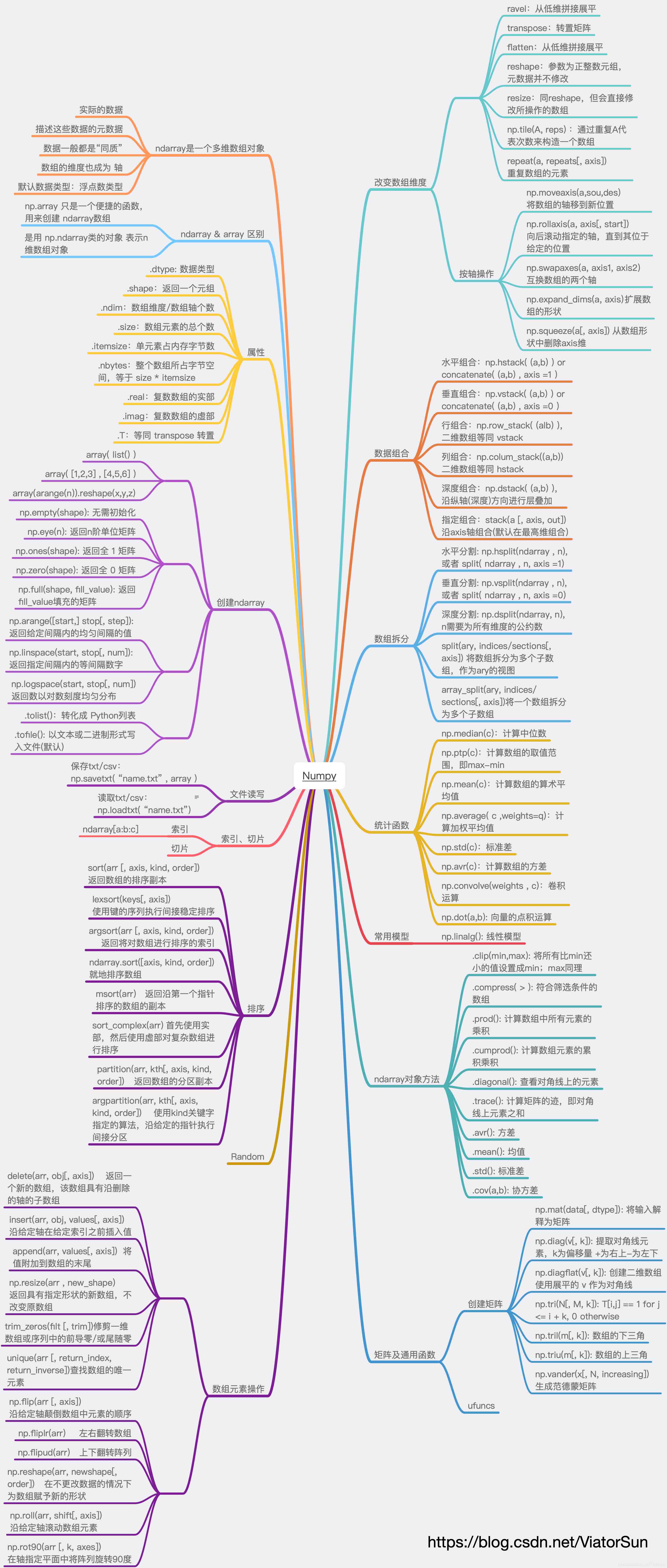
1、创建 Numpy 数组
NumPy提供了一个N维数组类型,即ndarray, 它描述了相同类型的“项目”集合。可以使用例如N个整数来索引项目。从数组中提取的项( 例如 ,通过索引)由Python对象表示, 其类型是在NumPy中构建的数组标量类型之一。 数组标量允许容易地操纵更复杂的数据排列。
ndarray 与 array 的区别
np.array 只是一个便捷的函数,用来创建一个ndarray,它本身不是一个类。
ndarray 数组,是用 np.ndarray类的对象 表示n维数组对象
所以ndarray是一个类对象,而array是一个方法。
创建数组有5种常规机制:
从其他Python结构(例如,列表,元组)转换
numpy原生数组的创建(例如,arange、ones、zeros等)
从磁盘读取数组,无论是标准格式还是自定义格式
通过使用字符串或缓冲区从原始字节创建数组
使用特殊库函数(例如,random)
1、np.array
一个 ndarray是具有相同类型和大小的项目的(通常是固定大小的)多维容器。 尺寸和数组中的项目的数量是由它的shape定义, 它是由N个非负整数组成的tuple(元组),用于指定每个维度的大小。 数组中项目的类型由单独的data-type object (dtype)指定, 其中一个与每个ndarray相关联。
与Python中的其他容器对象一样,可以通过对数组进行索引或切片(例如,使用N个整数)以及通过ndarray的方法和属性来访问和修改ndarray的内容。
不同的是,ndarrays可以共享相同的数据, 因此在一个ndarray中进行的更改可能在另一个中可见。 也就是说,ndarray可以是另一个ndarray 的 “view” ,它所指的数据由 “base” ndarray处理。 ndarrays也可以是Python拥有的内存strings或实现 buffer 或数组接口的对象的视图。
通过 np.array() np.ndarray() 创建
# Create an array.
np.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
np.ndarray(shape, dtype=float, buffer=None, offset=0, strides=None, order=None)
一个 ndarray是具有相同类型和大小的项目的多维容器。
尺寸和数组中的项目的数量是由它的shape定义, 它是由N个非负整数组成的tuple(元组),用于指定每个维度的大小。
不同的是,ndarrays可以共享相同的数据, 因此在一个ndarray中进行的更改可能在另一个中可见。 也就是说,ndarray可以是另一个ndarray 的 “view” ,它所指的数据由 “base” ndarray处理。 ndarrays也可以是Python拥有的内存strings或实现 buffer 或数组接口的对象的视图。
Examples:
>>> np.array([1, 2, 3])
array([1, 2, 3])
>>> np.array([1, 2, 3.0])
array([ 1., 2., 3.])
>>> np.array([[1, 2], [3, 4]])
array([[1, 2],
[3, 4]])
>>> np.array([1, 2, 3], ndmin=2)
array([[1, 2, 3]])
>>> np.array([1, 2, 3], dtype=complex)
array([ 1.+0.j, 2.+0.j, 3.+0.j])
>>> x = np.array([(1,2),(3,4)],dtype=[('a','i4'),('b','i4')])
>>> x['a']
array([1, 3])
>>> np.array(np.mat('1 2; 3 4'))
array([[1, 2],
[3, 4]])
>>> np.array(np.mat('1 2; 3 4'), subok=True)
matrix([[1, 2],
[3, 4]])
>>> np.ndarray(shape=(2,2), dtype=float, order='F')
array([[ -1.13698227e+002, 4.25087011e-303],
[ 2.88528414e-306, 3.27025015e-309]]) #random
>>> np.ndarray((2,), buffer=np.array([1,2,3]),
offset=np.int_().itemsize,
dtype=int) # offset = 1 * itemsize, i.e. skip first element
array([2, 3])
2、基本属性
数组属性反映了数组本身固有的信息。通常,通过其属性访问数组允许您获取并有时设置数组的内部属性,而无需创建新数组。公开的属性是数组的核心部分,只有一些属性可以有意义地重置而无需创建新数组。有关每个属性的信息如下。
内存布局
以下属性包含有关数组内存布局的信息:
方法 描 述
| ndarray.flags | 有关数组内存布局的信息。
| ndarray.shape | 数组维度的元组。
| ndarray.strides | 遍历数组时每个维度中的字节元组。
| ndarray.ndim | 数组维数。
| ndarray.data | Python缓冲区对象指向数组的数据的开头。
| ndarray.size | 数组中的元素数。
| ndarray.itemsize | 一个数组元素的长度,以字节为单位。
| ndarray.nbytes | 数组元素消耗的总字节数。
| ndarray.base | 如果内存来自其他对象,则为基础对象。
数据类型
可以在dtype属性中找到与该数组关联的数据类型对象 :
方法 | 描 述
| ndarray.dtype | 数组元素的数据类型。
其他属性
方法 | 描 述
| ndarray.T | 转置数组。
| ndarray.real | 数组的真实部分。
| ndarray.imag | 数组的虚部。
| ndarray.flat | 数组上的一维迭代器。
| ndarray.ctypes | 一个简化数组与ctypes模块交互的对象。
3、Numpy 原生数组 创建 ndarray
方法 | 描 述
| eye(N[, M, k, dtype, order]) | 返回一个二维数组,对角线上有一个,其他地方为零
| identity(n[, dtype]) | 返回标识数组。
| ones(shape[, dtype, order]) | 返回给定形状和类型的新数组,并填充为1
| ones_like(a[, dtype, order, subok, shape]) | 返回形状与类型与给定数组相同的数组。
| zeros(shape[, dtype, order]) | 返回给定形状和类型的新数组,并用零填充。
| zeros_like(a[, dtype, order, subok, shape]) | 返回形状与类型与给定数组相同的零数组。
| full(shape, fill_value[, dtype, order]) | 返回给定形状和类型的新数组,并用fill_value填充
| full_like(a, fill_value[, dtype, order, …]) | 返回形状和类型与给定数组相同的完整数组
| empty(shape[, dtype, order]) | 返回给定形状和类型的新数组,而无需初始化条目
| empty_like(prototype[, dtype, order, subok, …]) | 返回形状和类型与给定数组相同的新数组
zeros_like()、ones_like()、empty_like() 等带 _like() 的函数创建与参数数组的形状及类型相同的数组。
frombuffer()、fromstring()、fromfile() 等函数可以从字节序列或文件创建数组
4、np.arange
| 方法 | 描 述
| arange([start,] stop[, step,][, dtype]) | 返回给定间隔内的均匀间隔的值。
| linspace(start, stop[, num, endpoint, …]) | 返回指定间隔内的等间隔数字。
| logspace(start, stop[, num, endpoint, base, …]) | 返回数以对数刻度均匀分布。
| geomspace(start, stop[, num, endpoint, …]) | 返回数字以对数刻度(几何级数)均匀分布。
| meshgrid(*xi, **kwargs) | 从坐标向量返回坐标矩阵。
| mgridnd_grid | 实例,它返回一个密集的多维 “meshgrid”
| ogridnd_grid | 实例,它返回一个开放的多维 “meshgrid”
2、从现有的数据创建
方法 描 述
| array(object[, dtype, copy, order, subok, ndmin]) | 创建一个数组
| asarray(a[, dtype, order]) | 将输入转换为数组
| asanyarray(a[, dtype, order]) | 将输入转换为ndarray,但通过ndarray子类
| ascontiguousarray(a[, dtype]) | 返回内存中的连续数组(ndim > = 1)(C顺序)
| asmatrix(data[, dtype]) | 将输入解释为矩阵
| copy(a[, order]) | 返回给定对象的数组副本
| frombuffer(buffer[, dtype, count, offset]) | 将缓冲区解释为一维数组
| fromfile(file[, dtype, count, sep, offset]) | 根据文本或二进制文件中的数据构造一个数组
| fromfunction(function, shape, **kwargs) | 通过在每个坐标上执行一个函数来构造一个数组
| fromiter(iterable, dtype[, count]) | 从可迭代对象创建一个新的一维数组
| fromstring(string[, dtype, count, sep]) | 从字符串中的文本数据初始化的新一维数组
| loadtxt(fname[, dtype, comments, delimiter, …]) | 从文本文件加载数据
3、创建矩阵
方法 | 描 述
| mat(data[, dtype]) | 将输入解释为矩阵
| bmat(obj[, ldict, gdict]) | 从字符串,嵌套序列或数组构建矩阵对象
| tril(m[, k]) | 数组的下三角。
| triu(m[, k]) | 数组的上三角。
| vander(x[, N, increasing]) | 生成范德蒙矩阵
| diag(v[, k]) | 提取对角线或构造对角线数组。
| diagflat(v[, k]) | 使用展平的输入作为对角线创建二维数组。
| tri(N[, M, k, dtype]) | 在给定对角线处及以下且在其他位置为零的数组。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- Numpy ndarray 多维数组对象的使用
- numpy库ndarray多维数组的维度变换方法(reshape、resize、swapaxes、flatten)
- np.newaxis 实现为 numpy.ndarray(多维数组)增加一个轴
- numpy.ndarray 交换多维数组(矩阵)的行/列方法
- NumPy实现ndarray多维数组操作
