# -*- coding:utf-8 -*-
#python 2.7
#http://tieba.baidu.com/p/2460150866
#标签操作
from bs4 import BeautifulSoup
import urllib.request
import re
#如果是网址,可以用这个办法来读取网页
#html_doc = "http://tieba.baidu.com/p/2460150866"
#req = urllib.request.Request(html_doc)
#webpage = urllib.request.urlopen(req)
#html = webpage.read()
html="""
html>head>title>The Dormouse's story/title>/head>
body>
p class="title" name="dromouse">b>The Dormouse's story/b>/p>
p class="story">Once upon a time there were three little sisters; and their names were
a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" class="sister" id="xiaodeng">!-- Elsie -->/a>,
a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie/a> and
a href="http://example.com/tillie" rel="external nofollow" class="sister" id="link3">Tillie/a>;
a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" class="sister" id="xiaodeng">Lacie/a>
and they lived at the bottom of a well./p>
p class="story">.../p>
"""
soup = BeautifulSoup(html, 'html.parser') #文档对象
#查找a标签,只会查找出一个a标签
#print(soup.a)#a class="sister" href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" id="xiaodeng">!-- Elsie -->/a>
for k in soup.find_all('a'):
print(k)
print(k['class'])#查a标签的class属性
print(k['id'])#查a标签的id值
print(k['href'])#查a标签的href值
print(k.string)#查a标签的string
如果,标签a>中含有其他标签,比如em>../em>,此时要提取a>中的数据,需要用k.get_text()
soup = BeautifulSoup(html, 'html.parser') #文档对象
#查找a标签,只会查找出一个a标签
for k in soup.find_all('a'):
print(k)
print(k['class'])#查a标签的class属性
print(k['id'])#查a标签的id值
print(k['href'])#查a标签的href值
print(k.string)#查a标签的string
如果,标签a>中含有其他标签,比如em>../em>,此时要提取a>中的数据,需要用k.get_text()
通常我们使用下面这种模式也是能够处理的,下面的方法使用了get()。
html = urlopen(url)
soup = BeautifulSoup(html, 'html.parser')
t1 = soup.find_all('a')
print t1
href_list = []
for t2 in t1:
t3 = t2.get('href')
href_list.append(t3)
补充:python爬虫获取任意页面的标签和属性(包括获取a标签的href属性)
# coding=utf-8
from bs4 import BeautifulSoup
import requests
# 定义一个获取url页面下label标签的attr属性的函数
def getHtml(url, label, attr):
response = requests.get(url)
response.encoding = 'utf-8'
html = response.text
soup = BeautifulSoup(html, 'html.parser');
for target in soup.find_all(label):
try:
value = target.get(attr)
except:
value = ''
if value:
print(value)
url = 'https://baidu.com/'
label = 'a'
attr = 'href'
getHtml(url, label, attr)
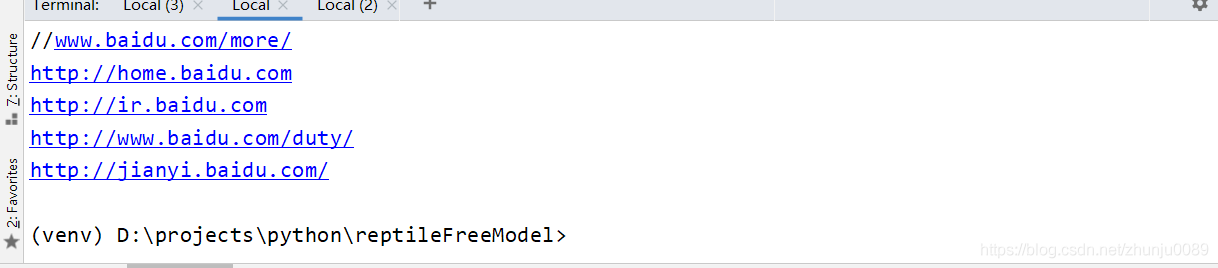
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。




