把文件夹dir1中后缀为'.jpg'的文件拷贝到文件夹dir2中:
import glob
import shutil
import sys
if __name__ == '__main__':
file_names = glob.glob('dir1/*.jpg')
for file_name in file_names:
try:
shutil.copy(file_name, 'dir2')
except:
print("Failed to copy file: ", sys.exc_info())
补充:Python之通配符--提取文件中的内容并输出
前言:
我的学习进度其实没有那么快的,因为现在是网络工程师实习,只有晚上一点时间和周末有空,所以周一到周天的学习进度很慢,今天之所以突然跳到通配符是因为工作需要,大体讲一下我的工作需求:网络工程师就是写脚本然后导入不同的网络设备中,我现在有一份现网正在使用的设备的命令,需要更换新的设备,但新设备跟旧设备(现网中正在使用的)不是同一个厂家的,导致他们的命令不兼容(知识,大体内容是一样的),所以我需要把旧设备中的Mac地址啦,ip啦,网关等全部提取出来并插入到新的命令模式中,现在开始完成上述需求(简单的,只包含一点关于IP-MAC绑定的,用于DHCP自动分配ip地址时可以根据PC的MAC和VLAN来获取特定的IP)
效果图:

旧设备中命令格式:

变动的大体形式:
原:
ip source binding 0000-0000-0014 vlan 20 1.1.1.14 interface FastEthernet 0/14
新:
int g1/0/14
ip source binding ip-address 1.1.1.14 mac-address 0000-0000-0014 vlan 20
源代码:
import re
f = open('C:/Users/Shinelon/Desktop/ceshi.txt','r',encoding = 'utf-8')
x = (f.readlines())
for i in range(0,51):
s = x[i]
mac = re.findall('.{4}-.{4}-.{4}', s)
ip = re.findall('\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}', s)
inter = re.findall('0/\d{1,2}', s)
vlan = re.findall('vlan \d\d', s)
inter = ''.join(inter)
mac = ''.join(mac)
vlan = ''.join(vlan)
ip = ''.join(ip)
print("int g1/%s" % inter)
print("ip source binding ip-address %s mac-address %s %s" % (ip, mac, vlan))
f.close()
解析
正则表达式,学网络的时候接触过,但比较浅,今天重新看了下各命令的含义,第一次写,有些可以精简的地方我都没精简,一个是太晚了没时间,另一个就是能力有限,多多包涵。
整体思路
从原文件中逐行取出,试了好几次,才弄好格式问题,必须txt,用word文档会报编码错误,pycharm默认的好像是uef-8,而word是gbk,导致不兼容,总之还得改软件的编码方式,我嫌太麻烦,同一使用txt,也挺方便的。
然后就是读取文件的格式,应该是open函数固定的,‘r'是指的只读,不往文档中写(f.close()是我写博客的时候刚加的,不知道对不对,就是关闭流,不关问题不大,报错就网上查查命令或删除)。
读取是readlines()(readline()没有s只读一行)读到文件尾,返回值是列表,且一次性读出(可以用循环,那样就要用readline()一行一行的读)。
然后通过创建“s”字符串和for循环来一个一个的处理文件列表的内容,之所以要用字符串是因为通配符只支持处理字符串!且通配符处理后的返回值为列表。
至于通配符规则,有点长也有点多,网上不少,可自行百度,我这里只提供思路。通配符匹配想要的数据(我这里提取了ip地址,mac地址,所属vlan,在哪个接口下),然后分别用不同的列表承接这些值用于方便打印。
需要注意的是,这里的列表不需要加索引,加了会报错,我也是搞了半天,因为这个列表是在for循环中的,每一次循环都相当于重新赋值创建,所以不存在说列表会增长,直接打印全部即可(可在循环外建列表,在循环内通过append方法增加列表长度)。
另一个需要注意的是,因为是列表,打印出来会带着“['']”,就很烦,不是我想要的命令那种一体化的,所以在这里我又查找到了join方法,属于列表常用方法,就是新建字符串(我特意看了下类型,下面有图说明),让字符串赋值:列表,并改变列表的分隔符(默认是单引号加逗号)为join前面单引号内的参数(可以为空None)。
我去,突然想到我前面最后一句打印的其实不是列表而是字符串,这样的话直接打印完整的一串毫无问题,前面的疑问解决,还是多总结的好啊,能发现不足,完善自己!
Join方法:
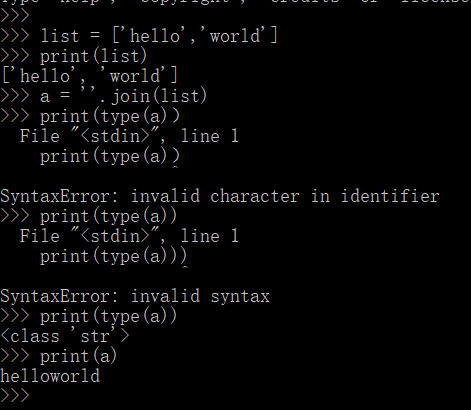
(请忽略那几个报错,是因为最后的括号是中文输入法的括号不识别报的错)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- python实现替换word中的关键文字(使用通配符)
- Python 实用技巧之利用Shell通配符做字符串匹配
- python中redis查看剩余过期时间及用正则通配符批量删除key的方法
- Python 通配符删除文件的实例
