层次分析法的基本思想是将复杂问题分为若干层次和若干因素,在同一层次的各要素之间简单地进行比较判断和计算,并评估每层评价指标对上一层评价指标的重要程度,确定因素权重,从而为选择最优方案提出依据。步骤如下:
只有当CR0.1,则认为该判断矩阵通过了一致性检验,即该矩阵自相矛盾产生的误差可忽略。将矩阵C最大特征根对应的特征向量元素作归一化处理,即可得到对应的权重集(C1,C2,…,Cn)。
由于层次分析法选用1-9标度构建判断矩阵,而大部分时候我们自己也不能很好度量重要性的程度,故赵中奇提出用-1,0,1三标度来构建判断矩阵。同时,自动调整判断矩阵,消除前后时刻主观比较重要性时的矛盾现象,即让矩阵变为一致性矩阵(CR=0)。构建并调整判断矩阵以及算权值向量的步骤如下:
"""
Created on Tue Jan 26 10:12:30 2021
自适应层数的层次分析法求权值
@author: lw
"""
import numpy as np
import itertools
import matplotlib.pyplot as plt
#自适应层数的层次分析法
class AHP():
'''
注意:python中list与array运算不一样,严格按照格式输入!
本层次分析法每个判断矩阵不得超过9阶,各判断矩阵必须是正互反矩阵
FA_mx:下一层对上一层的判断矩阵集(包含多个三维数组,默认从目标层向方案层依次输入判断矩阵。同层的判断矩阵按顺序排列,且上层指标不共用下层指标)
string:默认为'norm'(经典的层次分析法,需输入9标度判断矩阵),若为'auto'(自调节层次分析法,需输入3标度判断矩阵)
'''
#初始化函数
def __init__(self,FA_mx,string='norm'):
self.RI=np.array([0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49]) #平均随机一致性指标
if string=='norm':
self.FA_mx=FA_mx #所有层级的判断矩阵
elif string=='auto':
self.FA_mx=[]
for i in range(len(FA_mx)):
temp=[]
for j in range(len(FA_mx[i])):
temp.append(self.preprocess(FA_mx[i][j]))
self.FA_mx.append(temp) #自调节层次分析法预处理后的所有层级的判断矩阵
self.layer_num=len(FA_mx) #层级数目
self.w=[] #所有层级的权值向量
self.CR=[] #所有层级的单排序一致性比例
self.CI=[] #所有层级下每个矩阵的一致性指标
self.RI_all=[] #所有层级下每个矩阵的平均随机一致性指标
self.CR_all=[] #所有层级的总排序一致性比例
self.w_all=[] #所有层级指标对目标的权值
#输入单个矩阵算权值并一致性检验(特征根法精确求解)
def count_w(self,mx):
n=mx.shape[0]
eig_value, eigen_vectors=np.linalg.eig(mx)
maxeig=np.max(eig_value) #最大特征值
maxindex=np.argmax(eig_value) #最大特征值对应的特征向量
eig_w=eigen_vectors[:,maxindex]/sum(eigen_vectors[:,maxindex]) #权值向量
CI=(maxeig-n)/(n-1)
RI=self.RI[n-1]
if(n=2 and CI==0):
CR=0.0
else:
CR=CI/RI
if(CR0.1):
return CI,RI,CR,list(eig_w.T)
else:
print('该%d阶矩阵一致性检验不通过,CR为%.3f'%(n,CR))
return -1.0,-1.0,-1.0,-1.0
#计算单层的所有权值与CR
def onelayer_up(self,onelayer_mx,index):
num=len(onelayer_mx) #该层矩阵个数
CI_temp=[]
RI_temp=[]
CR_temp=[]
w_temp=[]
for i in range(num):
CI,RI,CR,eig_w=self.count_w(onelayer_mx[i])
if(CR>0.1):
print('第%d层的第%d个矩阵未通过一致性检验'%(index,i+1))
return
CI_temp.append(CI)
RI_temp.append(RI)
CR_temp.append(CR)
w_temp.append(eig_w)
self.CI.append(CI_temp)
self.RI_all.append(RI_temp)
self.CR.append(CR_temp)
self.w.append(w_temp)
#计算单层的总排序及该层总的一致性比例
def alllayer_down(self):
self.CR_all.append(self.CR[self.layer_num-1])
self.w_all.append(self.w[self.layer_num-1])
for i in range(self.layer_num-2,-1,-1):
if(i==self.layer_num-2):
temp=sum(self.w[self.layer_num-1],[]) #列表降维,扁平化处理,取上一层的权值向量
CR_temp=[]
w_temp=[]
CR=sum(np.array(self.CI[i])*np.array(temp))/sum(np.array(self.RI_all[i])*np.array(temp))
if(CR>0.1):
print('第%d层的总排序未通过一致性检验'%(self.layer_num-i))
return
for j in range(len(self.w[i])):
shu=temp[j]
w_temp.append(list(shu*np.array(self.w[i][j])))
temp=sum(w_temp,[]) #列表降维,扁平化处理,取上一层的总排序权值向量
CR_temp.append(CR)
self.CR_all.append(CR_temp)
self.w_all.append(w_temp)
return
#计算所有层的权值与CR,层次总排序
def run(self):
for i in range(self.layer_num,0,-1):
self.onelayer_up(self.FA_mx[i-1],i)
self.alllayer_down()
return
#自调节层次分析法的矩阵预处理过程
def preprocess(self,mx):
temp=np.array(mx)
n=temp.shape[0]
for i in range(n-1):
H=[j for j,x in enumerate(temp[i]) if j>i and x==-1]
M=[j for j,x in enumerate(temp[i]) if j>i and x==0]
L=[j for j,x in enumerate(temp[i]) if j>i and x==1]
DL=sum([[i for i in itertools.product(H,M)],[i for i in itertools.product(H,L)],[i for i in itertools.product(M,L)]],[])
DM=[i for i in itertools.product(M,M)]
DH=sum([[i for i in itertools.product(L,H)],[i for i in itertools.product(M,H)],[i for i in itertools.product(L,M)]],[])
if DL:
for j in DL:
if(j[0]j[1] and ij[0]):
temp[int(j[0])][int(j[1])]=1
if DM:
for j in DM:
if(j[0]j[1] and ij[0]):
temp[int(j[0])][int(j[1])]=0
if DH:
for j in DH:
if(j[0]j[1] and ij[0]):
temp[int(j[0])][int(j[1])]=-1
for i in range(n):
for j in range(i+1,n):
temp[j][i]=-temp[i][j]
A=[]
for i in range(n):
atemp=[]
for j in range(n):
a0=0
for k in range(n):
a0+=temp[i][k]+temp[k][j]
atemp.append(np.exp(a0/n))
A.append(atemp)
return np.array(A)
#%%测试函数
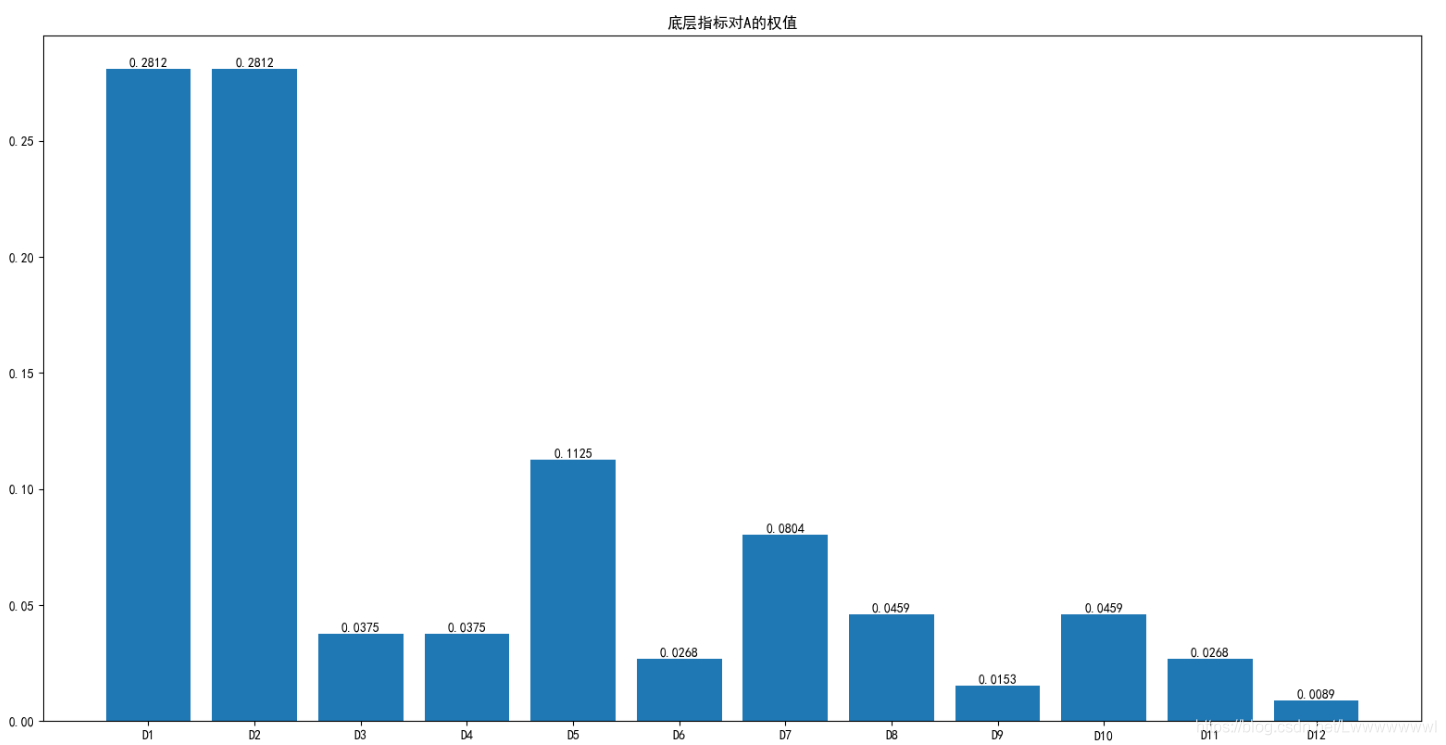
if __name__=='__main__' :
'''
# 层次分析法的经典9标度矩阵
goal=[] #第一层的全部判断矩阵
goal.append(np.array([[1, 3],
[1/3 ,1]]))
criteria1 = np.array([[1, 3],
[1/3,1]])
criteria2=np.array([[1, 1,3],
[1,1,3],
[1/3,1/3,1]])
c_all=[criteria1,criteria2] #第二层的全部判断矩阵
sample1 = np.array([[1, 1], [1, 1]])
sample2 = np.array([[1,1,1/3], [1,1,1/3],[3,3,1]])
sample3 = np.array([[1, 1/3], [3, 1]])
sample4 = np.array([[1,3,1], [1 / 3, 1, 1/3], [1,3, 1]])
sample5=np.array([[1,3],[1/3 ,1]])
sample_all=[sample1,sample2,sample3,sample4,sample5] #第三层的全部判断矩阵
FA_mx=[goal,c_all,sample_all]
A1=AHP(FA_mx) #经典层次分析法
A1.run()
a=A1.CR #层次单排序的一致性比例(从下往上)
b=A1.w #层次单排序的权值(从下往上)
c=A1.CR_all #层次总排序的一致性比例(从上往下)
d=A1.w_all #层次总排序的权值(从上往下)
e=sum(d[len(d)-1],[]) #底层指标对目标层的权值
#可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10','D11','D12']
plt.figure()
plt.bar(name,e)
for i,j in enumerate(e):
plt.text(i,j+0.005,'%.4f'%(np.abs(j)),ha='center',va='top')
plt.title('底层指标对A的权值')
plt.show()
'''
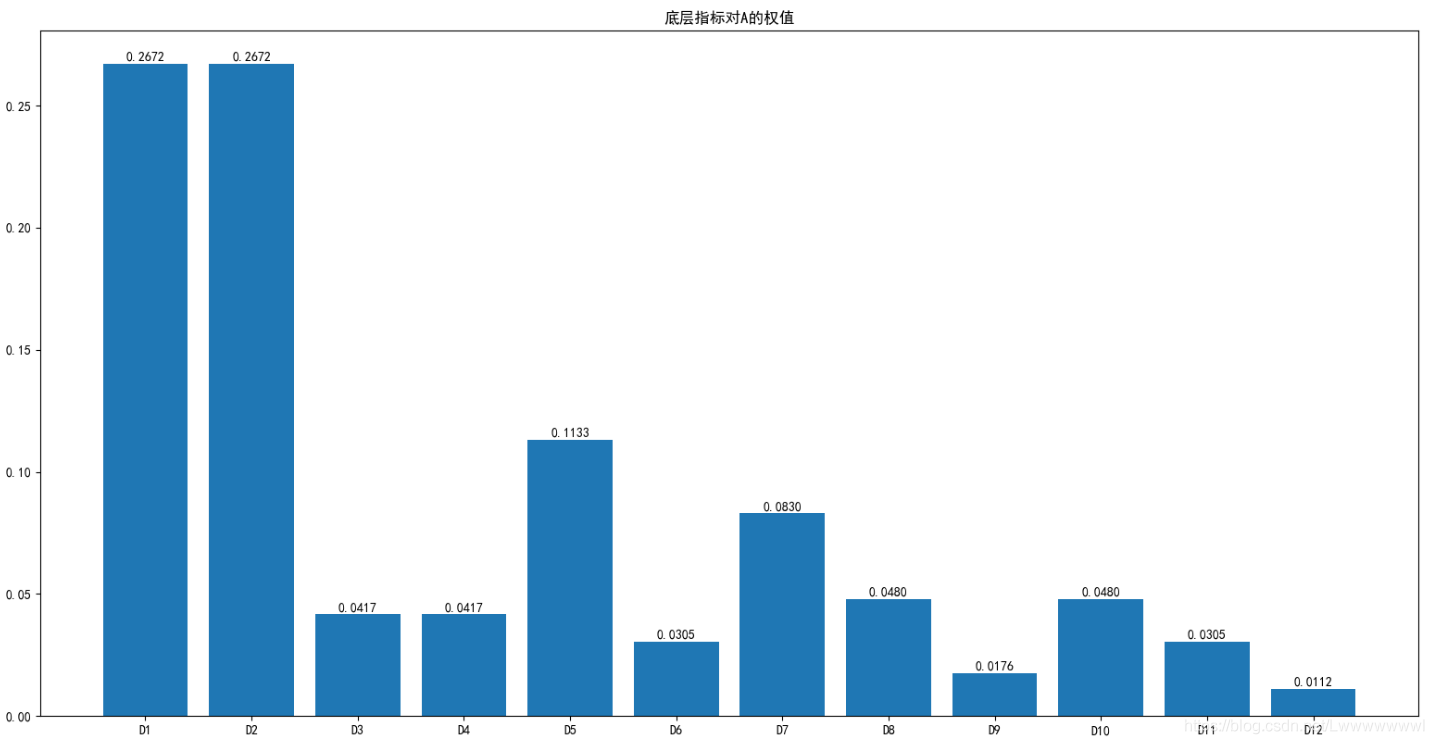
#自调节层次分析法的3标度矩阵(求在线体系的权值)
goal=[] #第一层的全部判断矩阵
goal.append(np.array([[0, 1],
[-1,0]]))
criteria1 = np.array([[0, 1],
[-1,0]])
criteria2=np.array([[0, 0,1],
[0,0,1],
[-1,-1,0]])
c_all=[criteria1,criteria2] #第二层的全部判断矩阵
sample1 = np.array([[0, 0], [0, 0]])
sample2 = np.array([[0,0,-1], [0,0,-1],[1,1,0]])
sample3 = np.array([[0, -1], [1, 0]])
sample4 = np.array([[0,1,0], [-1, 0,-1], [0,1,0]])
sample5=np.array([[0,1],[-1 ,0]])
sample_all=[sample1,sample2,sample3,sample4,sample5] #第三层的全部判断矩阵
FA_mx=[goal,c_all,sample_all]
A1=AHP(FA_mx,'auto') #经典层次分析法
A1.run()
a=A1.CR #层次单排序的一致性比例(从下往上)
b=A1.w #层次单排序的权值(从下往上)
c=A1.CR_all #层次总排序的一致性比例(从上往下)
d=A1.w_all #层次总排序的权值(从上往下)
e=sum(d[len(d)-1],[]) #底层指标对目标层的权值
#可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name=['D1','D2','D3','D4','D5','D6','D7','D8','D9','D10','D11','D12']
plt.figure()
plt.bar(name,e)
for i,j in enumerate(e):
plt.text(i,j+0.005,'%.4f'%(np.abs(j)),ha='center',va='top')
plt.title('底层指标对A的权值')
plt.show()
到此这篇关于Python实现层次分析法及自调节层次分析法的示例的文章就介绍到这了,更多相关Python 层次分析法及自调节层次分析法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!