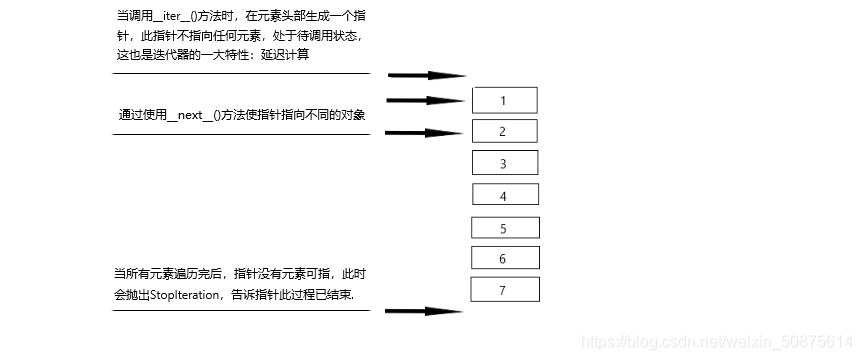
class A():
def __init__(self):
self.num = 1
def __call__(self):
x = self.num
self.num += 1
return x
a = A()
b = iter(a,5)
from collections import Iterable,Iterator
#我们可以看到a对象既不是可迭代对象也不是迭代器,但通过iter()方法返回的对象b确实迭代器
isinstance(a,Iterable) >>> False
isinstance(a,Iterator) >>> False
isinstance(b,Iterator) >>> True
isinstance(b,Iterable) >>> True
#通过for...in循环遍历打印(每次循环都调用__call__()方法,直至返回值等于5,触发StopIteration停止迭代)
for i in b:
print(i) >>> 1 2 3 4
#iter()的第二种形式的一个有用的应用是构建块读取器。例如,从二进制数据库文件中读取固定宽度的块,直到到达文件结尾:
from functools import partial
with open('mydata.db', 'rb') as f:
for block in iter(partial(f.read, 64), b''):
process_block(block)
2.直接调用可迭代对象的__iter__方法;
#定义__iter__()方法,可以返回自己,但自己要定义__next__()方法;也可以返回其他对象的迭代器
#第一种:返回自身,同时定义自身的__next__()方法
class A():
def __init__(self):
pass
def __iter__(self):
self.num = 0
return self
def __next__(self):
if self.num 10:
N = self.num
self.num += 1
return N
else:
raise StopIteration
a = A()
b = a.__iter__()
from collections import Iterable,Iterator
#由于A类中我们定义的__iter__()函数是返回自己,同时定义了自身的__next__()方法,所以对象a既是可迭代对象,又是迭代器。
isinstance(a,Iterable) >>> True
isinstance(a,Iterator) >>> True
#同时我们可以看到对象a经过iter()方法后生成的b对象是迭代器。
isinstance(b,Iterable) >>> True
isinstance(b,Iterator) >>> True
#第二种:返回其他对象的迭代器
class A():
def __init__(self):
pass
def __iter__(self):
self.num = 0
return b
class B(A):
def __next__(self):
if self.num 10:
N = self.num
self.num += 1
return N
else:
raise StopIteration
#实例化两个对象:a和b,当调用对象a的__iter__()方法时,返回对象b,B继承于A类,所以b对象是一个迭代器。
a = A()
b = B()
#调用a的__iter__()方法
c = a.__iter__()
from collections import Iterable,Iterator
#由于对象a不具备__next__()方法,因此仅仅是一个可迭代对象
isinstance(a,Iterable) >>> True
isinstance(a,Iterator) >>> False
#但是调用对象a的__iter()方法生成的c,同时具备__iter__()和__next__()方法,是一个迭代器。
isinstance(c,Iterable) >>> True
isinstance(c,Iterator) >>> True
#iter()函数:其运行机制是寻找对象中的__iter__()方法,运行并返回结果,如果__iter__()方法返回的不是迭代器,则此方法会报错;如果没有此方法,则寻找__getitem__()方法。
class A():
def __init__(self):
pass
def __iter__(self):
return 1 #我们知道数字1不是迭代器,此函数返回的是一个非迭代器
a = A()
b = iter(a)
Traceback (most recent call last):
File "input>", line 10, in module>
TypeError: iter() returned non-iterator of type 'int'
#直接调用__iter__()方法:如果想通过调用此方法生成迭代器,只能定义在此函数下返回一个迭代器;如果定义返回的不是迭代器,调用此方法是不会生成迭代器的。
class A():
def __init__(self):
pass
def __iter__(self):
return 1
a = A()
#直接调用__iter__()方法
b = a.__iter__()
#我们可以看到返回的是1,而不是迭代器,只有当你定义返回迭代器时,调用此方法才会返回迭代器
print(b) >>> 1
#我们定义一个类:具有__iter__()方法,但返回的不是迭代器
class A():
def __init__(self):
pass
def __iter__(self):
return 1
a = A()
from collections import Iterable
#我们使用isinstance()结合collections看一下:会发现此方法认为他是一个可迭代对象
isinstance(a,Iterable) >>> True
#我们使用for...in进行循环访问,发现并不能
for i in a:
print(i)
Traceback (most recent call last):
File "input>", line 1, in module>
TypeError: iter() returned non-iterator of type 'int'
#接下来,我们再定义一个类:具有__iter__()方法和__next__()方法,但返回的不是迭代器
class A():
def __init__(self):
pass
def __iter__(self):
pass
def __next__(self):
pass
a = A()
from collections import Iterator
#我们使用isinstance()结合collections看一下:会发现此方法认为他是一个迭代器
isinstance(a,Iterator) >>> True
#我们使用for...in进行循环访问,发现并不能
for i in a:
print(a)
Traceback (most recent call last):
File "input>", line 1, in module>
TypeError: iter() returned non-iterator of type 'NoneType'
2.使用iter()内置函数进行判断:
class A():
def __init__(self):
pass
def __iter__(self):
return 1
a = A()
#使用iter()函数如果报错,则不是可迭代对象,如果不报错,则是可迭代对象
b = iter(a)
Traceback (most recent call last):
File "input>", line 1, in module>
TypeError: iter() returned non-iterator of type 'int'
3.使用for…in方法进行遍历,如果可以遍历,即为可迭代对象
#for...in循环的实质是:先调用对象的__iter__()方法,返回一个迭代器,然后不断的调用迭代器的__next__()方法。
class A():
def __init__(self):
pass
def __iter__(self):
self.num = 0
return self
def __next__(self):
if self.num 10:
N = self.num
self.num += 1
return N
else:
raise StopIteration
a = A()
for i in a:
print(i) >>> 0 1 2 3 4 5 6 7 8 9
#等同于:先调用对象的__iter__()方法,返回一个迭代器,然后不断的调用迭代器的__next__()方法,调用完返回StopIteration,结束迭代
b = iter(a)
while True:
try:
next(b)
except:
raise StopIteration
0 1 2 3 4 5 6 7 8 9
Traceback (most recent call last):
File "stdin>", line 3, in module>
File "stdin>", line 13, in __next__
StopIteration
def A():
yield 1
yield 2
a = A()
print(a)
#可以看出a显示的是一个生成器对象
generator object A at 0x7f4f94409eb8>
#我们使用dir()函数看一下生成器的方法:
dir(a)
['省略', '__iter__', '省略', '__next__', 'send', 'throw','省略']
#可以看到生成器里面自动完成了对__iter__()和__next__()方法的定义
#我们调用对象的__iter__()方法
print(iter(a)) >>> generator object A at 0x7f4f94409eb8>
print(a) >>> generator object A at 0x7f4f94409eb8>
#可以看到,调用__iter__()方法,返回的是对象自己
#我们调用对象的__next__()方法
next(a) >>> 1
#可以看到,再次调用next()方法,是在上次的基础上继续运行的,返回的是2,而不是像普通函数一样,从头开始重新运行
next(a) >>> 2
next(a)
Traceback (most recent call last):
File "stdin>", line 1, in module>
StopIteration
#可以看到生成器a调用next()方法后生成下一个元素,同时当元素耗尽时,抛出StopIteration错误,这和迭代器完全相似
#生成器完全符合迭代器的要求,所以生成器也属于迭代器
除了定义一个yield函数外,还可以利用推导式生成一个生成器
#一般的推导式有列表推导式和字典推导式,与两者不同,生成器的推导式是写在小括号中的,而且只能是比较简单的生成器,比较复杂的生成器一般是写成yield函数的形式.
a = (i for i in range(5))
print(a)
generator object genexpr> at 0x03CFDE28>
类型
定义
判断方法
生成器
使用yield的函数,或者类似(i for i in range(5))这样的推导式,自动实现__iter__()和__next__()方法