对于非连续数据集,数据可视化时候需要每七天一个采样点。要求是选择此前最新的数据作为当日的数据展示,譬如今天是2019-06-18,而数据集里只有2019-06-15,那就用2019-06-15的数据作为2019-06-18的数据去描点。
每七天一个采样点,会使得每天展示所选的数据都会有所不同。当时间往后推移一天,日期为2019-06-19,那么最新数据点从2019-06-19开始,第二个就是2019-06-12。这里就需要一个算法来快速的根据当前日期去选出(填充)一系列数据供数据可视化之用。
先生成一串目标时间序列,从某个开始日到今天为止,每七天一个日期。
把这些日期map到数据集的日期, Eg. {“2019-06-18”:“2019-06-15”…} 。
把map到的数据抽出来用pd.concat接起来。
target_dates = pd.date_range(end=now, periods=100, freq="7D") full_dates = pd.date_range(start, now).tolist() org_dates = df.date.tolist() last_date = None for d in full_dates: if d in org_dates: date_map[d] = d last_date = d elif last_date is not None: date_map[d] = last_date else: continue new_df = pd.DataFrame() for td in target_dates: new_df = pd.concat([new_df, df[df["date"]==date_map[td]])
这样的一个算法处理一个接近千万量级的数据集上大概需要十多分钟。仔细检查发现,每一次合并的dataframe数据量并不小,而且总的操作次数达到上万次。
所以就想如何避免高频次地使用pd.concat去合并dataframe。
最终想到了一个巧妙的方法,只需要修改一下前面的第三步,把日期的map转换成dataframe,然后和原始数据集做merge操作就可以了。
target_dates = pd.date_range(end=now, periods=100, freq="7D")
full_dates = pd.date_range(start, now).tolist()
org_dates = df.date.tolist()
last_date = None
for d in full_dates:
if d in org_dates:
date_map[d] = d
last_date = d
elif last_date is not None:
date_map[d] = last_date
else:
continue
#### main change is from here #####
date_map_list = []
for td in target_dates:
date_map_list.append({"target_date":td, "org_date":date_map[td]})
date_map_df = pd.DataFrame(date_map_list)
new_df = date_map_df.merge(df, left_on=["org_date"], right_on=["date"], how="inner")
改进之后,所有的循环操作都在一个微数量级上,最后一个merge操作得到了所有有用的数据,运行时间在5秒左右,大大提升了性能。
补充:Pandas DataFrames 中 merge 合并的坑点(出现重复连接键)
在我的实际开发中遇到的坑点,查阅了相关文档 总结一下
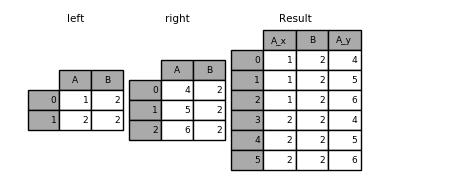
left = pd.DataFrame({'A': [1, 2], 'B': [2, 2]})

right = pd.DataFrame({'A': [4, 5, 6], 'B': [2, 2, 2]})

result = pd.merge(left, right, on='B', how='outer')
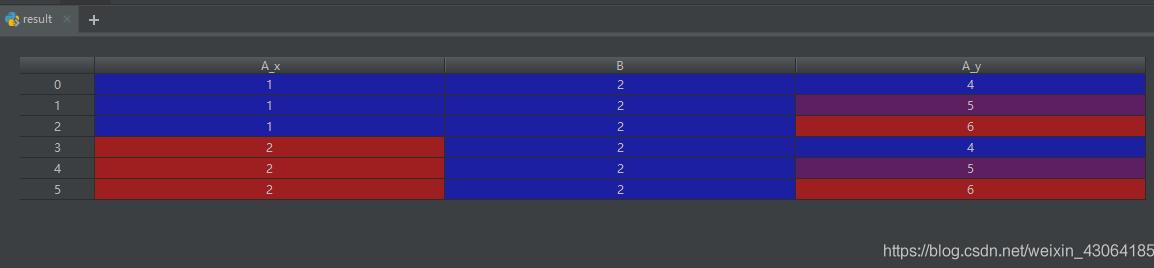
警告:在重复键上加入/合并可能导致返回的帧是行维度的乘法,这可能导致内存溢出。在加入大型DataFrame之前,重复值。
检查重复键
如果知道右侧的重复项DataFrame但希望确保左侧DataFrame中没有重复项,则可以使用该 validate='one_to_many'参数,这不会引发异常。
pd.merge(left, right, on='B', how='outer', validate="one_to_many") # 打印的结果: A_x B A_y 0 1 1 NaN 1 2 2 4.0 2 2 2 5.0 3 2 2 6.0
参数:
validate : str, optional If specified, checks if merge is of specified type. “one_to_one” or “1:1”: check if merge keys are unique in both left and right datasets. “one_to_many” or “1:m”: check if merge keys are unique in left dataset. “many_to_one” or “m:1”: check if merge keys are unique in right dataset. “many_to_many” or “m:m”: allowed, but does not result in checks.
官方文档连接:
Pandas文档中提及 merge
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。



上一篇:Pandas提取单元格的值操作
下一篇:python高效的素数判断算法

