下载谷歌浏览器驱动,并配置好
import time
import random
from PIL import Image
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
if __name__ == '__main__':
options = webdriver.ChromeOptions()
options.binary_location = r'C:\Users\hhh\AppData\Local\Google\Chrome\Application\谷歌浏览器.exe'
# driver=webdriver.Chrome(executable_path=r'D:\360Chrome\chromedriver\chromedriver.exe')
driver = webdriver.Chrome(options=options)
#以java模块为例
driver.get('https://www.csdn.net/nav/java')
for i in range(1,20):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(2)
from bs4 import BeautifulSoup
from lxml import etree
html = etree.HTML(driver.page_source)
# soup = BeautifulSoup(html, 'lxml')
# soup_herf=soup.find_all("#feedlist_id > li:nth-child(1) > div > div > h2 > a")
# soup_herf
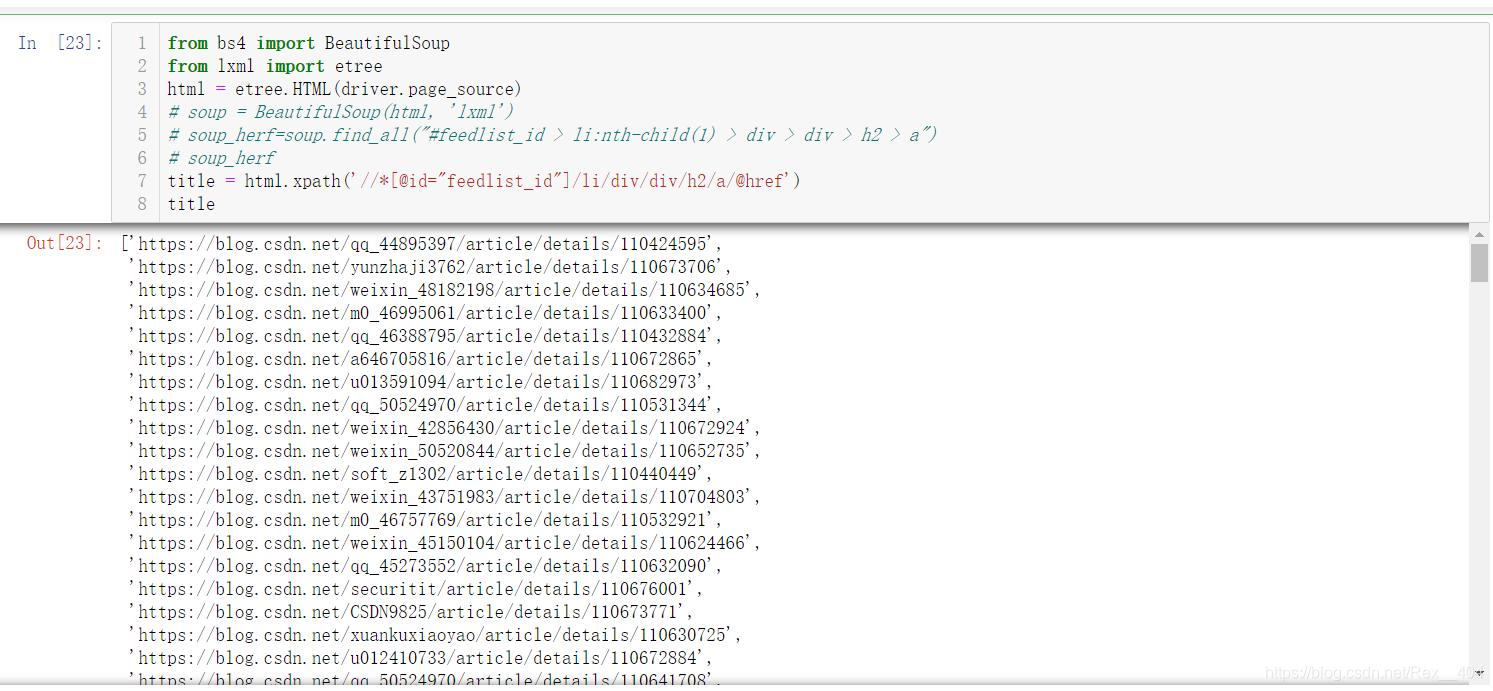
title = html.xpath('//*[@id="feedlist_id"]/li/div/div/h2/a/@href')
可以看到,一下爬取了很多,速度非常快
导入redis包后,配置redis端口和redis数据库,用rpush函数写入
打开redis
import redis
r_link = redis.Redis(port='6379', host='localhost', decode_responses=True, db=1)
for u in title:
print("准备写入{}".format(u))
r_link.rpush("csdn_url", u)
print("{}写入成功!".format(u))
print('=' * 30, '\n', "共计写入url:{}个".format(len(title)), '\n', '=' * 30)
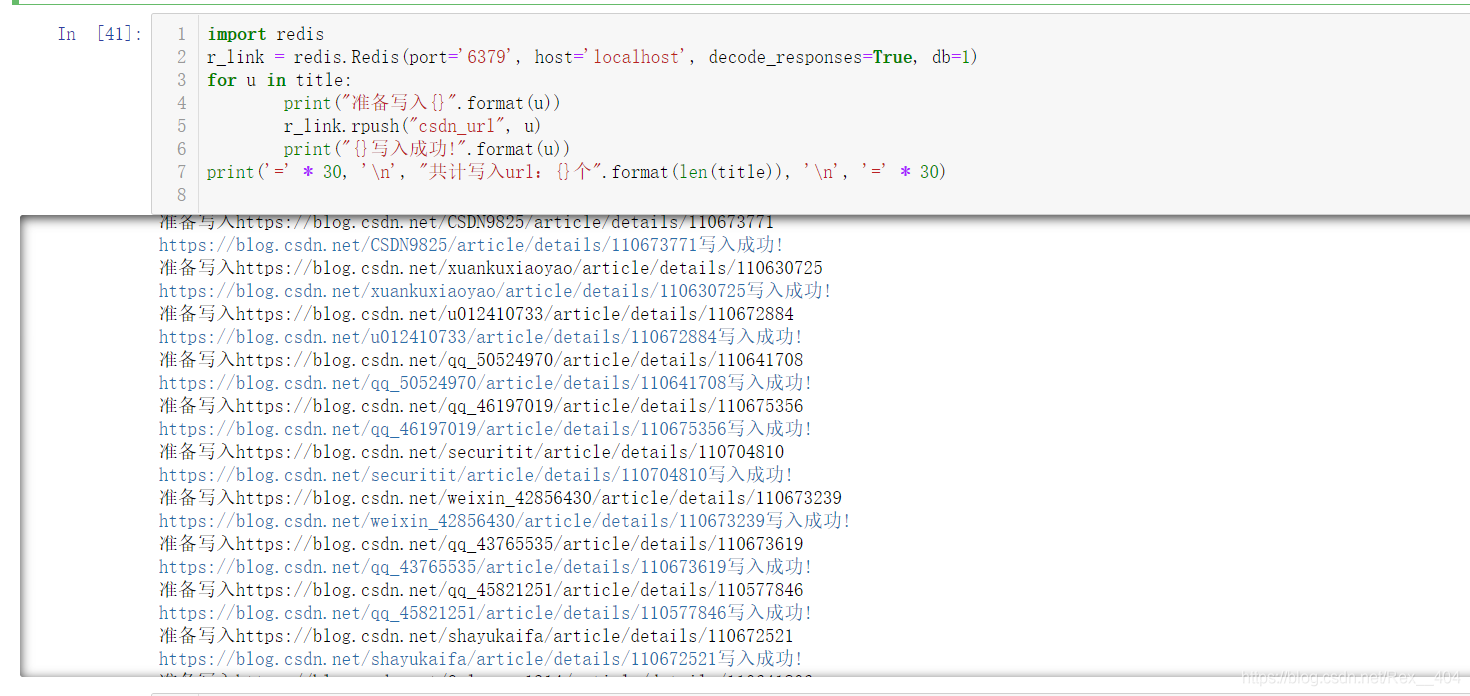
大功告成!
在Redis Desktop Manager中可以看到,爬取和写入都是非常的快。

要使用只需用rpop出栈就OK
one_url = r_link.rpop("csdn_url)")
while one_url:
print("{}被弹出!".format(one_url))
到此这篇关于详解用python实现爬取CSDN热门评论URL并存入redis的文章就介绍到这了,更多相关python爬取URL内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!




