代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 1. 定义Person类
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def watch_tv(self):
print(f'{self.name} 看电视')
# 2. 定义loop函数
# 打印 1-max 中的奇数
def test_person():
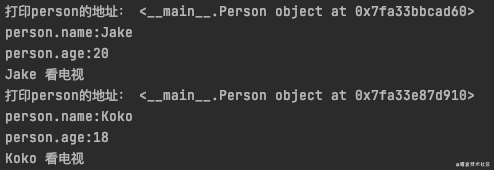
person = Person('Jake', 20)
print(f'打印person的地址:', person)
print(f'person.name:{person.name}')
print(f'person.age:{person.age}')
person.watch_tv()
person = Person('Koko', 18)
print(f'打印person的地址:', person)
print(f'person.name:{person.name}')
print(f'person.age:{person.age}')
person.watch_tv()
# 3. 执行calculate方法
# 计算 当前值小于1,当前值:0
# 计算 1 >= 1: True
# 计算 2 >= 1: True
# 计算 10 >= 1: True
test_person()
执行结果:
代码块:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# pip3 install pymysql
import pymysql
from getpass import getpass
# from mysql.connector import connect, Error
#
host = 'xxxxxxx'
port = 3306
username = 'db_account_member'
password = 'db_account_password'
database = 'some_database'
def connect_db():
return pymysql.connect(host=host,
port=port,
user=username,
password=password,
database=database,
charset='utf8')
def print_error(e):
print(f'错误类型:{type(e)}')
print(f'错误内容:{e}')
def close_gracefully(cursor, conn):
if cursor:
cursor.close()
if conn:
conn.close()
# 查询数据库,可以写任意查询语句
def query(sql):
try:
conn = connect_db() # 创建连接
cursor = conn.cursor() # 建立游标
cursor.execute(sql) # 执行sql语句
return cursor.fetchall()
except pymysql.Error as e:
print_error(e)
finally:
close_gracefully(cursor, conn)
query_sql = 'select * from category where id = 1'
rows = query(query_sql)
print('category表中的数据如下:')
print(rows)
执行结果:

代码:
# -*- coding: UTF-8 -*-
# 1. 导入csv库
import csv
file_name = '../resources/test.csv'
# 2. 定义headers和rows
headers = ['index', 'name', 'sex', 'height', 'year']
rows = [
[1, 'Jake', 'male', 177, 20],
[2, 'Koko', 'female', 165, 18],
[3, 'Mother', 'female', 163, 45],
[4, 'Father', 'male', 172, 48]
]
# 3. 定义write_csv函数
# 写入csv
def write_csv():
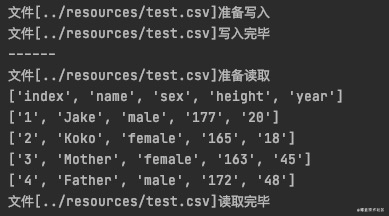
print(f'文件[{file_name}]准备写入')
with open(f'{file_name}', 'w')as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
print(f'文件[{file_name}]写入完毕')
# 读取csv
def read_csv():
print(f'文件[{file_name}]准备读取')
with open(f'{file_name}')as f:
f_csv = csv.reader(f)
for row in f_csv:
print(row)
print(f'文件[{file_name}]读取完毕')
# 4. 执行write_csv函数
write_csv()
print('------')
read_csv()
执行结果:
代码:
# -*- coding: UTF-8 -*-
# 导引
# 安装相关依赖
# pip3 install xlrd
# 引入xlrd去支持读取xls相关的文件
import xlrd
# 定义文件名
file_name = '../resources/sku.xls'
# 1. 读取xls文件
# 预计输出
# sku.xls该文档有 3 个tab页
sku_file = xlrd.open_workbook(file_name)
print("{0}该文档有 {1} 个tab页".format(file_name, sku_file.nsheets))
print("每个tab页,页名分别为: {0}".format(sku_file.sheet_names()))
# 2. 读取xls文件第1页
# 预计输出
# tab页名:Sheet1,该tab页共有59行,3列
# A6方格的值:1908165140370878
current_sheet_index = 0 # 下标0为第一页tab
current_sheet = sku_file.sheet_by_index(current_sheet_index)
print("tab页名:{0},该tab页共有{1}行,{2}列".format(current_sheet.name, current_sheet.nrows, current_sheet.ncols))
print("A6方格的值:{0}".format(current_sheet.cell_value(rowx=5, colx=0)))
# 3. 打印每页的数据,每一行的数据为一个数组
# 预计输出
# [text:'1908154975415329', text:'鞋面是织物 鞋底是聚氨酯底的哦', text:'鞋底是5厘米 内增是3厘米 总高度是8厘米左右哦']
# [text:'1908040228021948', text:'鞋面是飞织 鞋底是聚氨酯底的哦', text:'鞋底高度是3厘米左右哦']
# ...以下省略后续打印
for rx in range(current_sheet.nrows):
print(current_sheet.row(rx))
执行结果:

代码:
import platform
import pdfkit
# 这里根据自己的系统修改对应的wkhtmltopdf安装路径,修改其中一个就行了
win_path = 'D:/tools/wkhtmltopdf'
non_win_path = '/usr/local/bin/wkhtmltopdf'
def wkhtmltopdf_path():
system = platform.system()
if system == 'Darwin':
print('苹果系统,可以生成pdf')
path = non_win_path
elif system == 'Windows':
print('Windows系统,可以生成pdf')
path = win_path
elif system == 'Linux系统':
print('Linux系统,可以生成pdf')
path = non_win_path
else:
print('其他系统,暂不支持生成pdf')
raise Exception('其他系统,暂不支持生成pdf')
return path
def pre_config():
return pdfkit.configuration(wkhtmltopdf=wkhtmltopdf_path())
# 从链接地址生成pdf
def generate_pdf_from_url(url, output_file_path):
config = pre_config()
pdfkit.from_url(url, output_file_path)
# 从字符串生成pdf
def generate_pdf_from_string(str, output_file_path):
config = pre_config()
pdfkit.from_string(str, output_file_path)
generate_pdf_from_url('https://baidu.com', '../temp/baidu_test.pdf')
generate_pdf_from_string('hello', '../temp/hello.pdf')
wkhtmltopdf这个东西一定要装,不然无法生成pdf,会报IO方面的错误,小白照做就可以,不需要理解
执行结果

生成的文件长这个样子
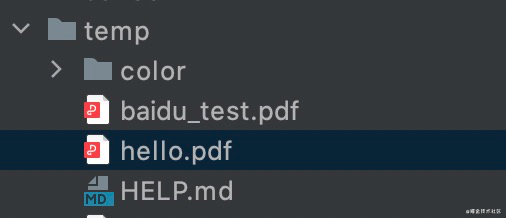
baidu_test.pdf

hello.pdf

以上就是python操作mysql、excel、pdf的示例的详细内容,更多关于python操作mysql、excel、pdf的资料请关注脚本之家其它相关文章!




