在命令行窗口下输入scrapy startproject scrapytest, 如下
然后就自动创建了相应的文件,如下
打开scrapy框架自动创建的items.py文件,如下
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ScrapytestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
编写里面的代码,确定我要获取的信息,比如新闻标题,url,时间,来源,来源的url,新闻的内容等
class ScrapytestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() timestamp = scrapy.Field() category = scrapy.Field() content = scrapy.Field() url = scrapy.Field() pass
在命令行窗口下面 创建一个crawl爬虫模板(注意在文件的根目录下面,指令检查别输入错误,-t 表示使用后面的crawl模板),会在spider文件夹生成一个news163.py文件
scrapy genspider -t crawl codingce news.163.com
然后看一下这个‘crawl'模板和一般的模板有什么区别,多了链接提取器还有一些爬虫规则,这样就有利于我们做一些深度信息的爬取
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
支持xpath和css,xpath语法如下
/html/head/title /html/head/title/text() //td (深度提取的话就是两个/) //div[@class=‘mine']
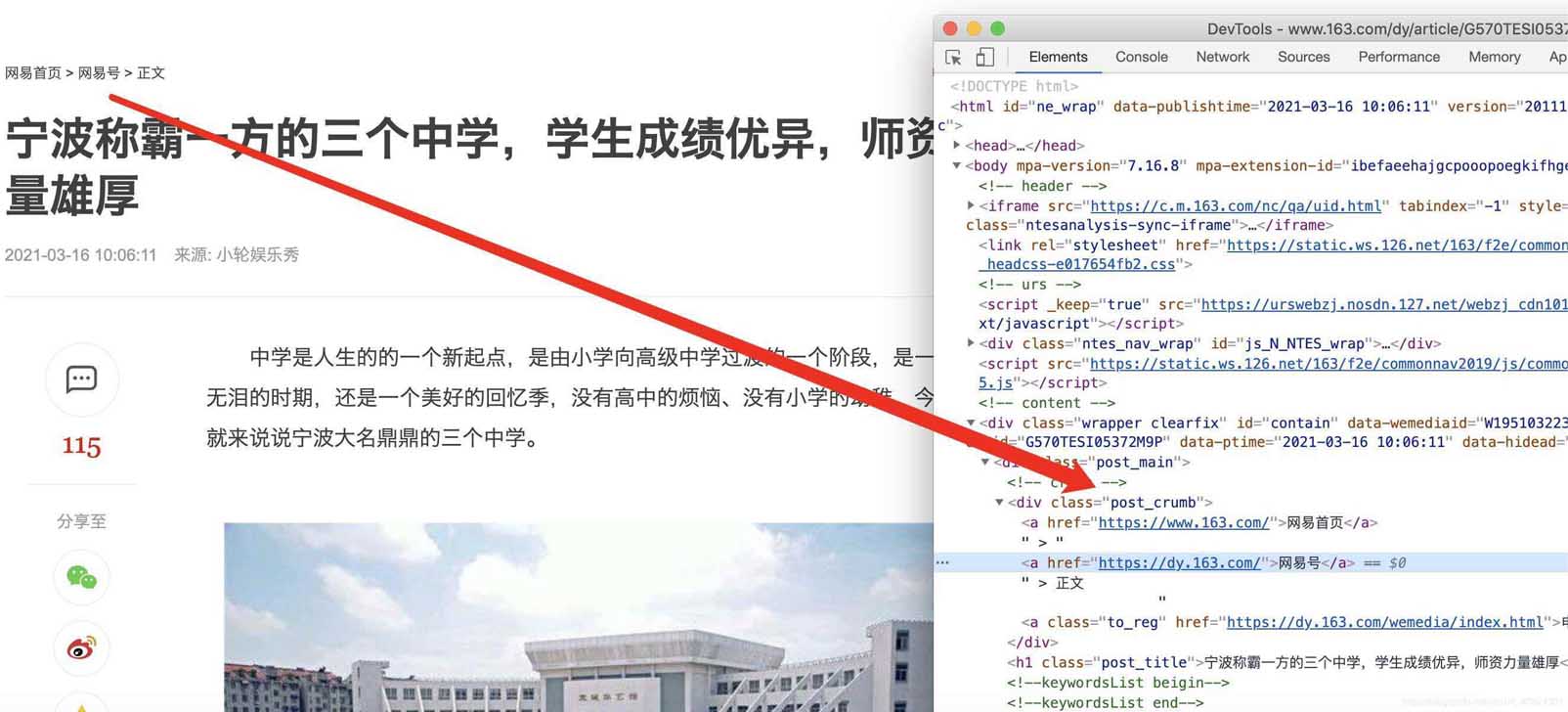
在谷歌chrome浏览器下,打在网页新闻的网站,选择查看源代码,确认我们可以获取到itmes.py文件的内容(其实那里面的要获取的就是查看了网页源代码之后确定可以获取的)
确认标题、时间、url、来源url和内容可以通过检查和标签对应上,比如正文部分
主体

标题
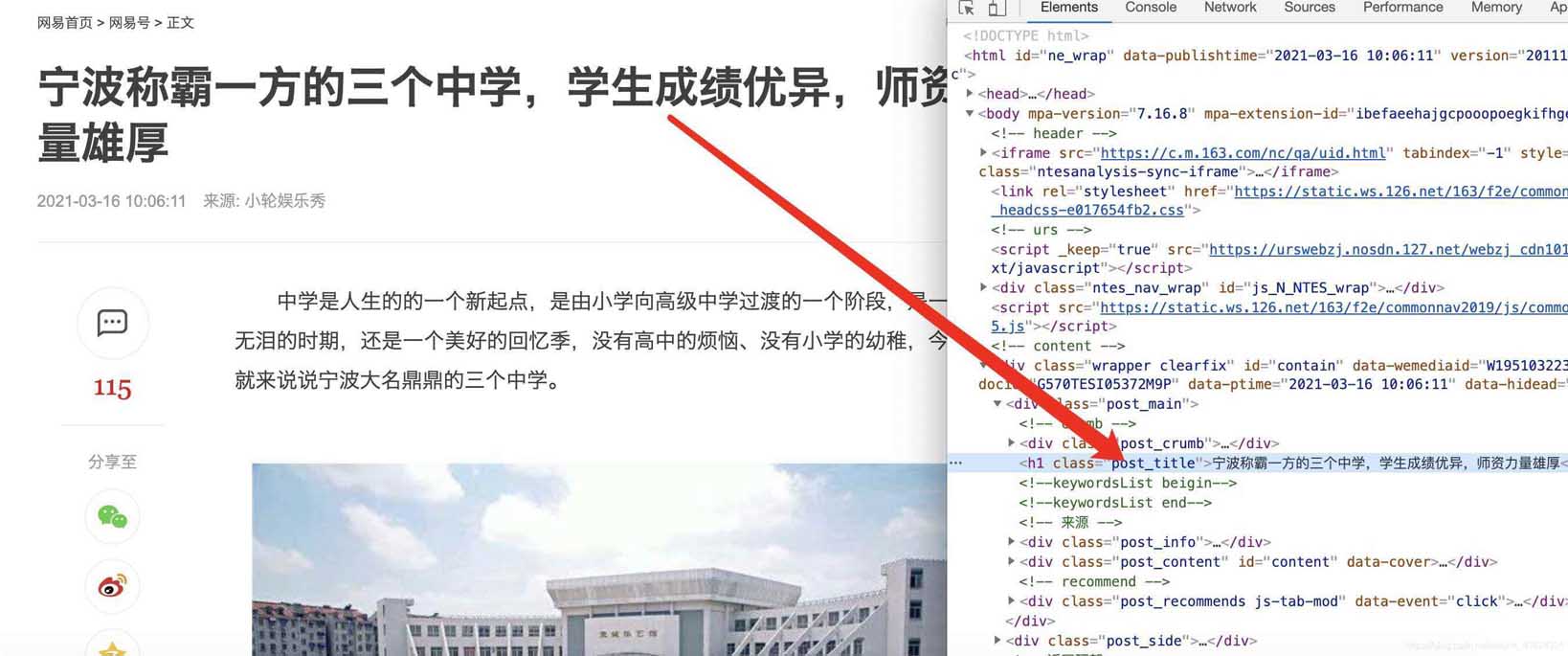
时间
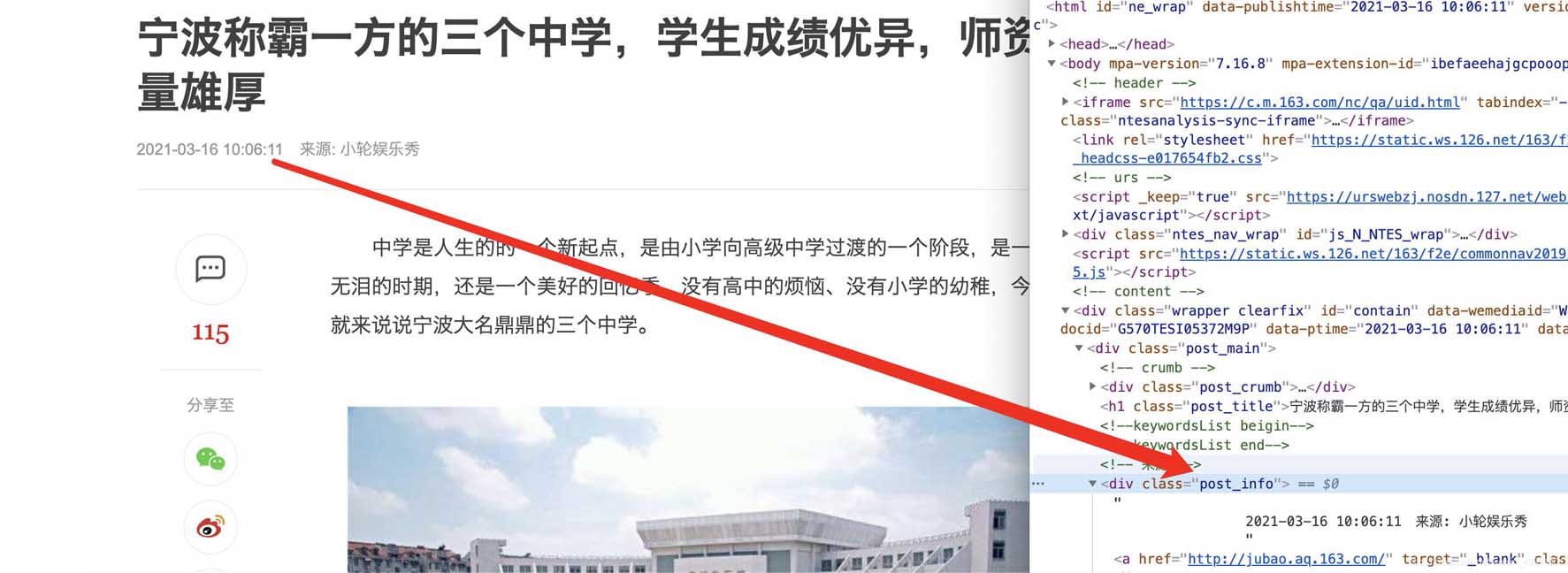
分类
打开创建的爬虫模板,进行代码的编写,除了导入系统自动创建的三个库,我们还需要导入news.items(这里就涉及到了包的概念了,最开始说的–init–.py文件存在说明这个文件夹就是一个包可以直接导入,不需要安装)
注意:使用的类ExampleSpider一定要继承自CrawlSpider,因为最开始我们创建的就是一个‘crawl'的爬虫模板,对应上
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = 'br>'.join(response.css('.post_content p::text').getall())
if len(content) 100:
return
return item
Rule(LinkExtractor(allow=r'..163.com/\d{2}/\d{4}/\d{2}/..html'), callback=‘parse', follow=True), 其中第一个allow里面是书写正则表达式的(也是我们核心要输入的内容),第二个是回调函数,第三个表示是否允许深入
最终代码
from datetime import datetime
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = 'br>'.join(response.css('.post_content p::text').getall())
if len(content) 100:
return
title = response.css('h1::text').get()
category = response.css('.post_crumb a::text').getall()[-1]
print(category, "=======category")
time_text = response.css('.post_info::text').get()
timestamp_text = re.search(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', time_text).group()
timestamp = datetime.fromisoformat(timestamp_text)
print(title, "=========title")
print(content, "===============content")
print(timestamp, "==============timestamp")
print(response.url)
return item
到此这篇关于python实现Scrapy爬取网易新闻的文章就介绍到这了,更多相关python Scrapy爬取网易新闻内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!



下一篇:NumPy 矩阵乘法的实现示例

