机器学习中,当我们在进行数据预处理的时候,对于标签列非字符的数据,我们往往需要将其转换成字符,因为有的算法可能不支持非数字类型来做特征。
那么怎么快捷地来着这个转换呢,请看我的示例:
import pandas as pd array = ['good','bad','well','bad','good','good','well','good']
df = pd.DataFrame(array,columns=['status']) status_dict = df['status'].unique().tolist()
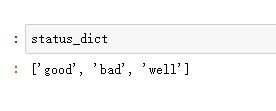
df['transfromed']=df['status'].apply(lambda x : status_dict.index(x))

这样,就将标签列处理好了哈
等用完之后,再转回来
df['transfromed1']= df['transfromed'].apply(lambda x : status_dict[x])

补充:pandas factorize将字符串特征转化为数字特征
将原始数据中的字符串特征转化为模型可以识别的数字特征可是使用pandas自带的factorzie方法。
原始数据的job特征值如下

都是字符串特征,无法用于训练,当然可以单独建立map硬编码处理,但是pandas已经封装好了相应的方法。
data = pd.read_csv("data/test_set.csv")
data["job"] = pd.factorize(data["job"])[0].astype(np.uint16)

以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。




