文章目录 微信登录问题Python chrome driver操作导入库并声明浏览器:完整流程:用js来预约生成js代码 主函数——程序出错时尝试:检测是否成功:logging: 生成每天的日志文件 Windows定时任务后记:
学校的图书馆需要网上预约。复习考研的人多、疫情座位少,约上一个好点的座位对于我这种经常忘记事情的懒人来说很难。
考虑到老师实验室有一台供我们使用的Windows服务器是不会关机的,正好可以帮我在早上7:00预约系统开启的时候执行程序去预约一个座位。所以产生了这个想法。
微信登录问题
想用chromedriver去操作,方便快捷,但我们图书馆的预约在微信上进行的,在微信公众号上认证过帐号以后,会发送一个链接,点进去就是自己的登录信息。经过和同学的验证,他将他的链接发送给我,我就可以打开他的登录信息。这让我感到很神奇,本以为登录信息仅仅携带在网址上,但如果在微信中用浏览器打开,再将网址复制到其它浏览器,会登陆失败。查找一系列百度谷歌想弄清楚这个问题,应该与cookies之类的有关,这里希望以后可以填坑。
当我没有找到头绪的时候,我偶然间发现学校图书馆开放了另一个入口可以在网页上预约,而这个流程就清晰很多了:
- 进入网站
- 输入账号和密码,点击登录按钮
- 找到座位并选择
Python chrome driver操作
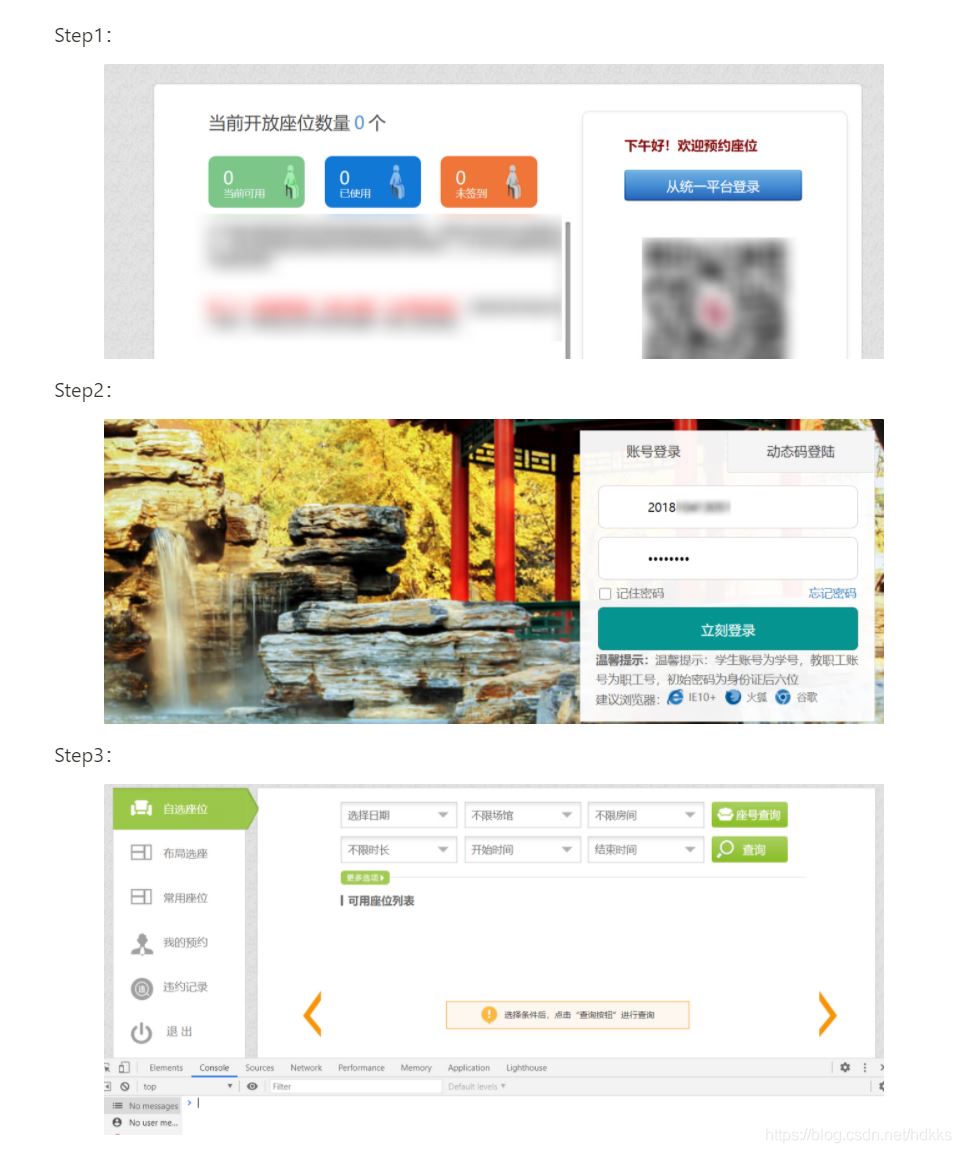
有几个注意的点:
- 每天早上系统开放的时间有几分钟的差别,需要留时间尝试。
- 刚开放的时候,系统会很卡,所以很可能会出现获取元素失败之类的情况。
这就要求我们的程序得有足够的鲁棒性(哈哈蛤) 容错能力,不会一下崩了就没用了。
所以我选择用try...except...的方法去进行,写了好多个try, 希望能找到不写这么多Try的更好的方法。
导入库并声明浏览器:
from selenium import webdriver
option = webdriver.ChromeOptions()
url='网址'
local_dir = 'C:\\Users\\Administrator\\Desktop\\librarytest\\' #webdiriver 位置
browser = webdriver.Chrome(local_dir+"chromedriver.exe",options=option)
完整流程:
使用selenium操作非常简单,就是find_element_by_id()和find_element_by_xpath(),主要是看F12去找他们的xpath或者id。
def wholeProcess(browser):
browser.get(url)
try:
btn=browser.find_element_by_xpath("/html/body/div[4]/div[2]/div[2]/dl/input") #找到登录的按钮,如果没找到证明还没到开放时间/系统在崩溃
except:
return 1 #1说明预约还没到时候
'''执行到这里说明打开啦'''
try:
btn.click()
username=browser.find_element_by_id("un")
password=browser.find_element_by_id("pd")#找到账号密码
username.send_keys(studentNumber)
password.send_keys(loginPassword)
btn=browser.find_element_by_xpath('//*[@id="index_login_btn"]/input')#找到登录按键
btn.click()
js=generateJsCode(startTime,endTime)#使用js代码来预约
res=browser.execute_script(js)
return 0
except:
return 2 #2说明打开了网页,但是遇到了其它问题
用js来预约
找到座位并选择,如果用鼠标操作的话是很繁琐的,包括先找到座位图标,点击,下拉选择开始时间和结束时间,再点击预约,这个过程麻烦不说,主要是容易出错。
而其实一个座位预定的本质其实是提交一个表单。浏览器的前端做了那么多人性化的操作,如可视化座位表、下拉框、温馨提示等,就是为了人使用时好看而又方便,而我们作为计算机就可以饶过他,直接提交表单。这里用的是selenium的execute_script()函数,可以用来执行网页上的js代码。
生成js代码
用F12去观察发现,图书管的表单提交需要下面几步:
$("#date").val("2020-12-10");
$("#reserveForm#seat").val("13022"); //座位号
$("#start").val("540"); //用分钟表示的时间 : 540=9*60 即九点
$("#end").val("1260");
$("#reserveForm").submit();
因此这个函数用来生成js代码:
def generateJsCode(startTime_ori,endTime_ori):
seatnumber_str = seatId
startTime_str = str(startTime_ori * 60)
endTime_str = str(endTime_ori * 60)
tomorrowTime = (datetime.datetime.now() + datetime.timedelta(days=1)).strftime('%Y-%m-%d') # 明天
js = '$("#date").val("' + tomorrowTime + '");$("#reserveForm #seat").val("' + seatnumber_str + '");$("#start").val("' + startTime_str + '");$("#end").val("' + endTime_str + '");$("#reserveForm").submit();'
return js
主函数——程序出错时尝试:
返回的状态中,如果网页没打开,让他休息10s再尝试,如果是其它原因,那么休息0.5秒就继续尝试:
if __name__=='__main__':
browser = webdriver.Chrome(local_dir+"chromedriver.exe",options=option)#声明浏览器
while True:
state=wholeProcess(browser)
if state==0: #没出错
break:
elif state==1:
logger.info("打开网页失败")
time.sleep(10)
elif state==2:
logger.info("其它错误")
time.sleep(0.5)
检测是否成功:
除了上面提到的网页崩溃导致WebDriver报错,还有几种可能导致失败:
- 座位被人抢了😟
- 已经有过预约了
- 有人约了但不是全部时间段。
这几种错误都不会报错,会在执行代码后以标签的形式告诉我们,可以用关键字定位这些标签,如果失败可以选择预约PlanB:
比如:
try:
a=browser.find_element_by_xpath("//*[contains(text(),'尽快')]") #有人约了(非全部时间)
error_reason=a.text
isNoSeat=True
logging: 生成每天的日志文件
写好小程序以后,几个兄弟听说了也想尝试,每天预约。
不想每天早上七点起来看,为了防止为止错误发生后还不知道是哪步出错,采取的办法是写日志文件(事后追责),这里使用的是logging这个包。
logger的初始化代码来源 : python的logging模块
import logging
# 创建一个logger
logger = logging.getLogger('mylogger')
logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(local_dir+'logfile\\'+logname+'.log')
fh.setLevel(logging.DEBUG)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 定义handler的输出格式
formatter = logging.Formatter('[%(asctime)s][%(thread)d][%(filename)s][line: %(lineno)d][%(levelname)s] ## %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)
# 记录一条日志
记录时只要使用 logger.info("xxxxx")就可以,非常方便,写在了上面。
Windows定时任务
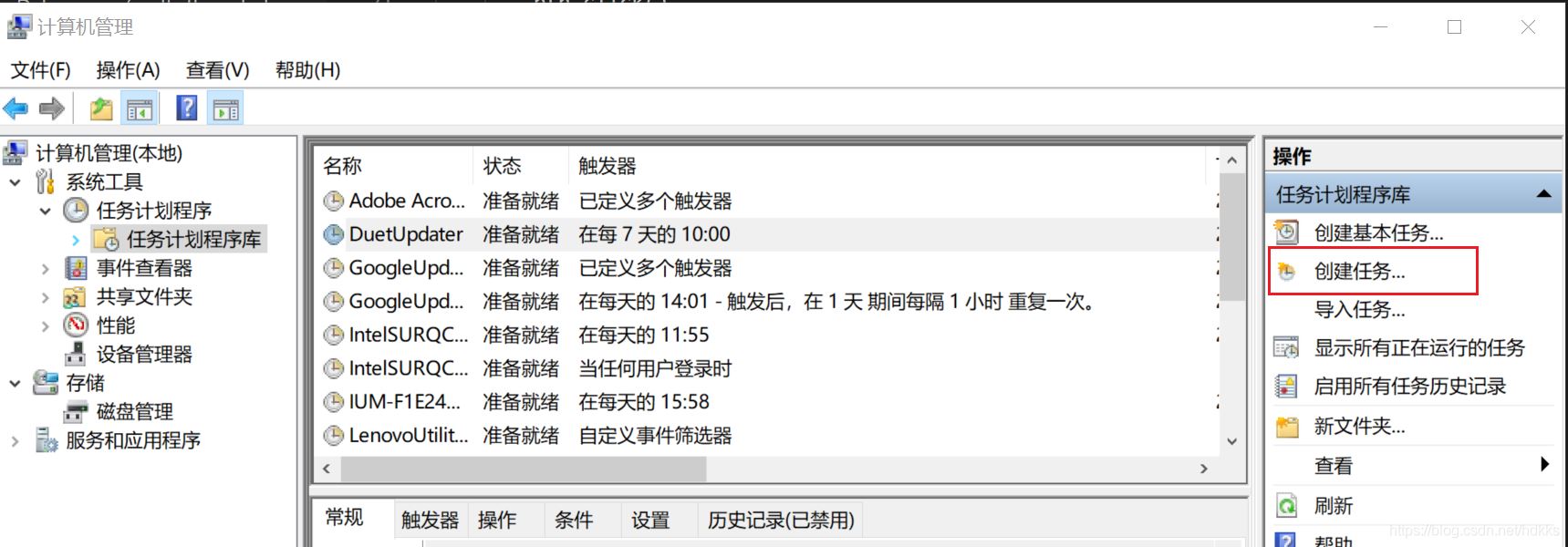
- 在触发器选项卡中新建,并设定时间
- 在操作选项卡中新建,并选择程序路径(下图)

这样就程序就会每天早上执行,只要有一台不关机的电脑。
后记:
大家开始使用我的代码,但都是我放在学校的服务器上,为了方便他们修改自己想要的预约时间、位置等信息,我写了个微信小程序方便同学修改时间。
思路就是使用微信小程序修改自己的预约信息,同步到微信的数据库。
早上预约时,我的程序通过微信云开发数据库的API获取到这些预约信息(时间、座位、学号、密码),再去预约,免去了总要去服务器上修改程序/参数的麻烦事。
具体的小程序部分的内容这里不展开,以后再写日记。
这就是上学期快期末的时候搞的一个小事情,虽然原理非常简单,但能帮自己和同学去预约图书馆还是很快乐的,尤其是每天早上醒来大家都收到企业微信的“预约成功”的提示的时候,然而过程中还有一些没懂的知识和没填的坑,所以在CSDN写个小记,怕以后忘了。
到此这篇关于使用Python webdriver图书馆抢座自动预约的正确方法的文章就介绍到这了,更多相关Python webdriver图书馆抢座自动预约内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
您可能感兴趣的文章:- 用python-webdriver实现自动填表的示例代码
- python+webdriver自动化环境搭建步骤详解
- selenium+python自动化测试之使用webdriver操作浏览器的方法
- python使用webdriver爬取微信公众号
- python实现图书馆抢座(自动预约)功能的示例代码
- python实现图书馆研习室自动预约功能
- Python Requests模拟登录实现图书馆座位自动预约

