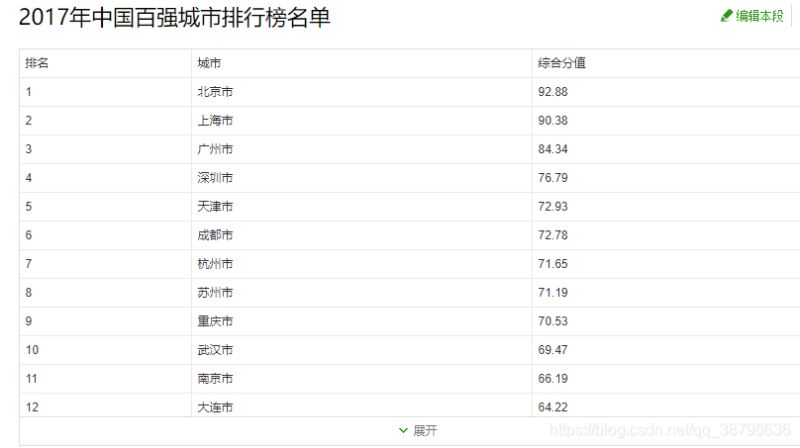
首先介紹一下我們用360搜索派取城市排名前20。
我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html
我们要爬取的内容:
html字段:

robots协议:
现在我们开始用python IDLE 爬取

import requests
r = requests.get("https://baike.so.com/doc/24368318-25185095.html")
r.status_code
r.text
结果分析,我们可以成功访问到该网页,但是得不到网页的结果。被360搜索识别,我们将headers修改。
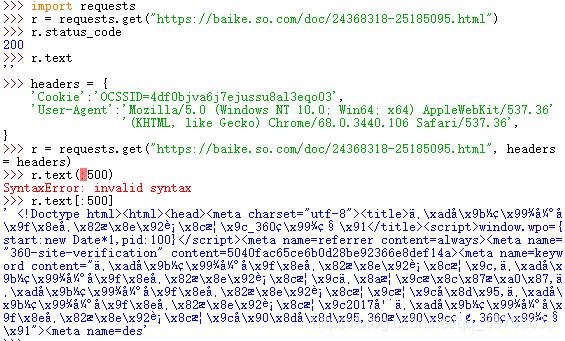
输出有个小插曲,网页内容很多,我是想将前500个字符输出,第一次格式错了
import requests
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.text
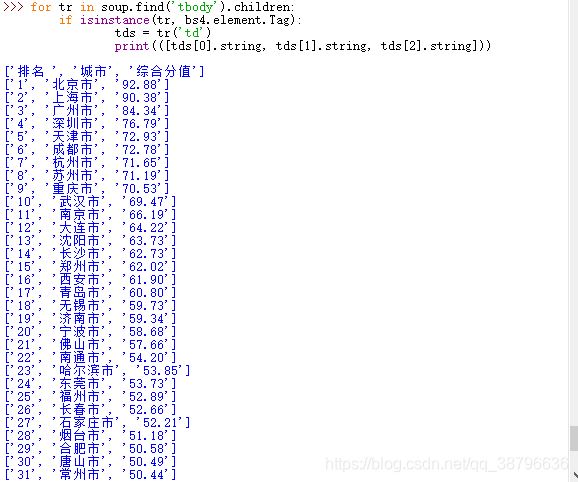
接着我们对需要的内容进行爬取,用(.find)方法找到我们内容位置,用(.children)下行遍历的方法对内容进行爬取,用(isinstance)方法对内容进行筛选:
import requests
from bs4 import BeautifulSoup
import bs4
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
print([tds[0].string, tds[1].string, tds[2].string])
得到结果如下:
修改输出的数目,我们用Clist列表来存取所有城市的排名,将前20个输出代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
Clist = list() #存所有城市的列表
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.encoding = r.apparent_encoding #将html的编码解码为utf-8格式
soup = BeautifulSoup(r.text, "html.parser") #重新排版
for tr in soup.find('tbody').children: #将tbody标签的子列全部读取
if isinstance(tr, bs4.element.Tag): #筛选tb列表,将有内容的筛选出啦
tds = tr('td')
Clist.append([tds[0].string, tds[1].string, tds[2].string])
for i in range(21):
print(Clist[i])
最终结果:
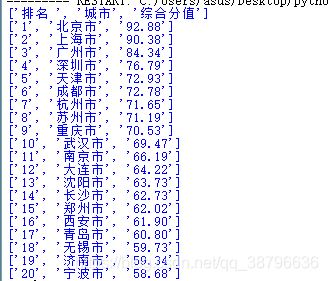
到此这篇关于Python用requests库爬取返回为空的解决办法的文章就介绍到这了,更多相关Python requests返回为空内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
标签:海南 哈尔滨 合肥 大庆 乌兰察布 郴州 乌兰察布 平顶山
巨人网络通讯声明:本文标题《Python用requests库爬取返回为空的解决办法》,本文关键词 Python,用,requests,库爬,取,;如发现本文内容存在版权问题,烦请提供相关信息告之我们,我们将及时沟通与处理。本站内容系统采集于网络,涉及言论、版权与本站无关。



