交叉表(cross-tabulation,简称crosstab)是⼀种⽤于计算分组频率的特殊透视表。
语法详解:
pd.crosstab(index, # 分组依据
columns, # 列
values=None, # 聚合计算的值
rownames=None, # 列名称
colnames=None, # 行名称
aggfunc=None, # 聚合函数
margins=False, # 总计行/列
dropna=True, # 是否删除缺失值
normalize=False #
)
1 crosstab() 实例1
1.1 读取数据
import os
import numpy as np
import pandas as pd
file_name = os.path.join(path, 'Excel_test.xls')
df = pd.read_excel(io=file_name, # 工作簿路径
sheetname='透视表', # 工作表名称
skiprows=1, # 要忽略的行数
parse_cols='A:D' # 读入的列
)
df
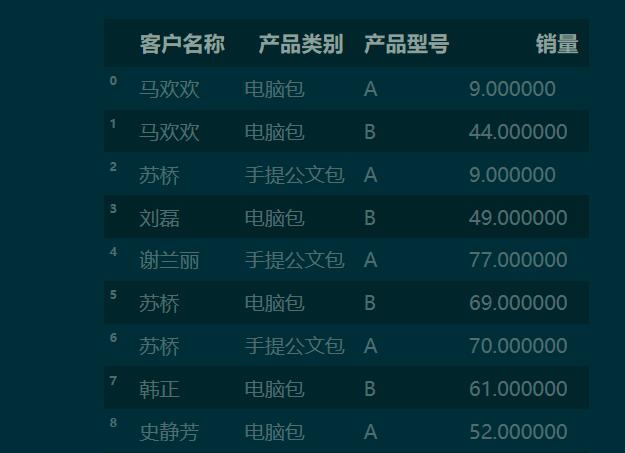
1.2 pd.crosstab() 默认生成以行和列分类的频数表
pd.crosstab(df['客户名称'], df['产品类别'])
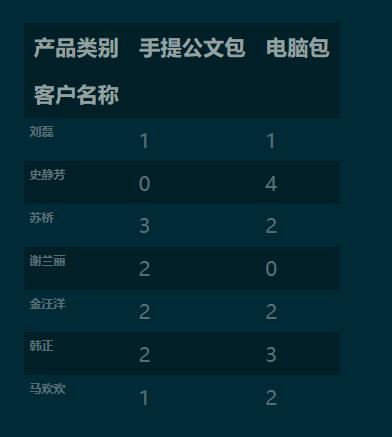
1.3 设置跟多参数实现分类汇总
pd.crosstab(index=df['客户名称'],
columns=df['产品类别'],
values=df['销量'],
aggfunc='sum',
margins=True
).round(0).fillna(0).astype('int')

注:因为交叉表示透视表的特例,所以交叉表可以用透视表的函数实现。又因为透视表可以用更 python 的方式 groupby-apply 实现,所以,交叉表完全可以用 groupby-apply 的方式实现。
2 用分类汇总的方法实现 交叉表
df.groupby(['客户名称', '产品类别']).apply(sum)
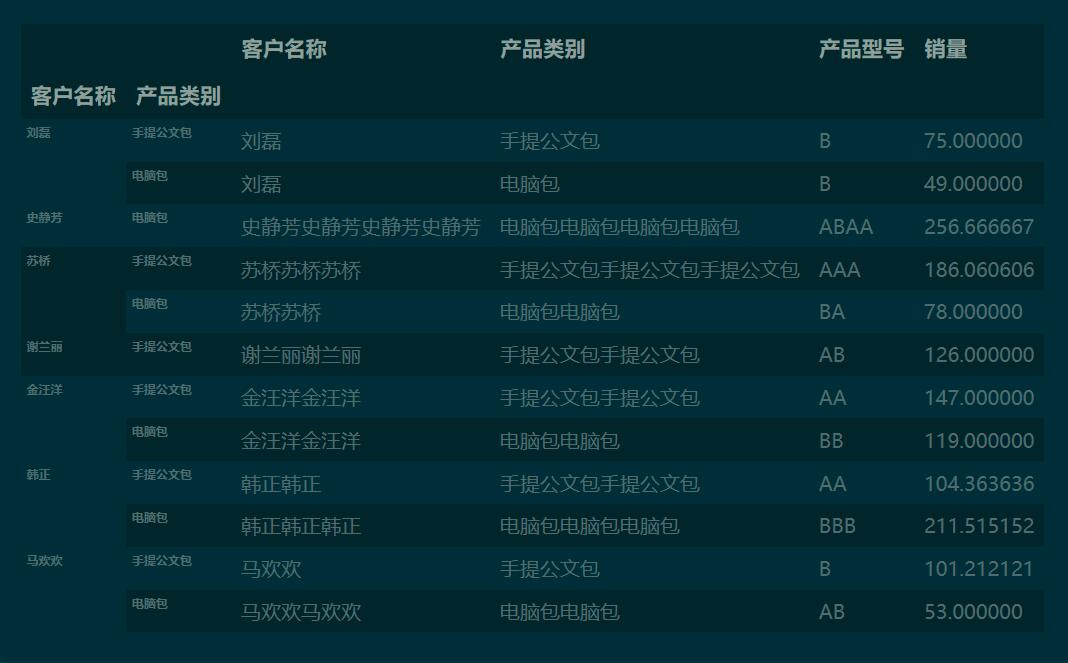
2.1 分类汇总、重新索引、设置数值格式综合应用
c_tbl = df.groupby(['客户名称', '产品类别']).apply(sum)['销量'].unstack()
c_tbl['总计'] = c_tbl.sum(axis=1) # 添加总计列
c_tbl.fillna(0).round(0).astype('int')

软件信息:

补充:使用python(pandas)将数据处理成交叉分组表
交叉分组表是汇总两种变量数据的方法, 在很多场景可以用到, 本文会介绍如何使用pandas将包含两个变量的数据集处理成交叉分组表.
环境
pandas
python 2.7
原理
用坐标轴来进行比喻, 其中一个变量作为x轴, 另一个作为y轴, 如果定位到数据则累加一, 将所有数据遍历一遍, 最后的坐标轴就是一张交叉分组表(使用坐标轴展示的数据一般是连续的, 交叉分组表的数据是离散的).
具体实现
示例数据:
quality price
0 bad 18
1 bad 17
2 great 52
3 good 28
4 excellent 88
5 great 63
6 bad 8
7 good 22
8 good 68
9 excellent 98
10 great 53
11 bad 13
12 great 62
13 good 48
14 excellent 78
15 great 63
16 good 37
17 great 69
18 good 28
19 excellent 81
20 great 43
21 good 32
22 great 62
23 good 28
24 excellent 82
25 great 53
代码:
import pandas as pd
from pandas import DataFrame, Series
#生成数据
df = DataFrame([['bad', 18], ['bad', 17], ['great', 52], ['good', 28], ['excellent', 88], ['great', 63]
, ['bad', 8], ['good', 22], ['good', 68], ['excellent', 98], ['great', 53]
, ['bad', 13], ['great', 62], ['good', 48], ['excellent', 78], ['great', 63]
, ['good', 37], ['great', 69], ['good', 28], ['excellent', 81], ['great', 43]
, ['good', 32], ['great', 62], ['good', 28], ['excellent', 82], ['great', 53]], columns = ['quality', 'price'])
#广播使用的函数
def quality_cut(data):
s = Series(pd.cut(data['price'], np.arange(0, 100, 10)))
return pd.groupby(s, s).count()
#进行分组处理
df.groupby(df['quality']).apply(quality_cut)
结果:
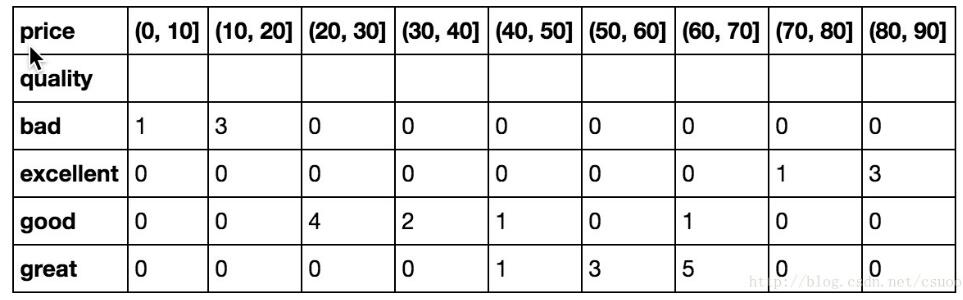
交叉分组
详细分析
从逻辑上来看, 为了达到对示例数据的交叉分组, 需要完成以下工作:
将数据以quality列进行分组.
将每个分组的数据分别进行cut, 以10为间隔.
将cut过的数据, 以cut的范围为列进行分组
将所有数据组合到一起, row为quality, columns为cut的范围
步骤1, pandasgroupby(...)接口, 会按照指定的列进行分组处理, 每一个分组, 存储相同类别的数据
class 'pandas.core.frame.DataFrame'>
quality price
0 bad 18
1 bad 17
6 bad 8
11 bad 13
而我们需要的, 只是price这列的数据, 所以单独将这列拿出来, 进行cut, 最后得到我们要的series(步骤2, 步骤3)
price
(0, 10] 1
(10, 20] 3
(20, 30] 0
(30, 40] 0
(40, 50] 0
(50, 60] 0
(60, 70] 0
(70, 80] 0
(80, 90] 0
使用pandas
apply()的广播特性, 每一个分组的数据都会经过上述几个步骤的处理, 最后与第一次分组row进行组合.
后记
估计能力有限, 这个问题想了很长时间, 没想到pandas这么可以这么方便达成交叉分组的效果. 思考的时候主要是卡在数据组合上, 当数据量很大时通过多个步骤进行数据组合, 肯定是低效而且错误的. 最后仔细研究了groupby, dataframe, series, dataframeIndex等数据模型, 使用广播特性用几句代码就完成了. 证明了pandas的高性能, 也提醒自己遇见问题一定要耐心分析。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
您可能感兴趣的文章:- python基于Pandas读写MySQL数据库
- python中pandas.read_csv()函数的深入讲解
- python pandas合并Sheet,处理列乱序和出现Unnamed列的解决
- python 使用pandas同时对多列进行赋值
- python之 matplotlib和pandas绘图教程
- Python3 pandas.concat的用法说明
- python pandas模糊匹配 读取Excel后 获取指定指标的操作
- 聊聊Python pandas 中loc函数的使用,及跟iloc的区别说明
- python Polars库的使用简介

