Worksheet 对象的 rows 属性和 columns 属性得到的是一 Generator 对象,不能用中括号取索引。
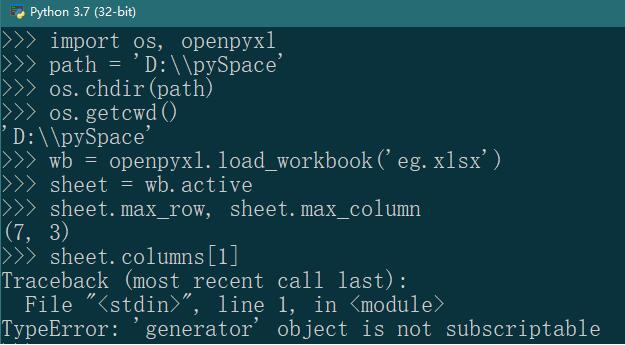
可先用列表推导式生成包含每一列中所有单元格的元组的列表,在对列表取索引。

Worksheet 的 rows 属性亦可用相同的方法处理。

补充:python之表格数据读取
python 操作excel主要用到xlrd,xlwt这两个库,xlrd,是读取excel表,xlwt是写入表格
table = xlrd.open("path_to_your_excel", 'rb')
一般时候需要进行判断,防止表格打开错误
try:
table = xlrd.open("path_to_your_excel", 'rb')
except Exception, e
print str(e)
当表格打开错误时,可以捕获异常
那么需要用到哪个工作簿
python 提供了三种获取方式
sheet1 = table.sheet()[1] or
sheet1 = table.sheet_by_index() or
sheet1 =table.sheet_by_name("sheetname")
那么根据需求,python提供了获取表格行数列数的方法
获取行数:nrows = sheet.nrows
获取列数:ncols = sheet.cols
返回值type为int
获取列数或行数可能是为了后续需要进行遍历内部的数据而用,那么下面来说python提供可以获取某一行或者某一列值的方法
获取某一行的值:
nrow_value = sheet.row_values(number)
获取某一列的值:
ncol_value = sheet.col_values(number)
#上面row_values(number)中的表示想要获取哪一行的索引值,比如获取第一行的值,就是row_values(0)
返回值的type为list
整行整列的数据获取,python给出了直接的方法,那么获取整张表数据呢,就需要用到for循环进行遍历每一个单元格
data_list = [] title = sheet.row_values(0) for i in range(1, sheet.nrows): data_values = OrderedDict() row_value = sheet.row_values(i) #从第二行开始遍历,根据行数获得每行的数据list for j in range(0, len(row_value)): data_values[title[j]] = row_value[j] print ([title[j]], row_value[j])data_list.append(data_values) # result = json.dumps(data_list) #需要转化成为json格式 return data_list
以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。
标签:哈尔滨 大庆 乌兰察布 乌兰察布 平顶山 海南 郴州 合肥
巨人网络通讯声明:本文标题《python 利用openpyxl读取Excel表格中指定的行或列教程》,本文关键词 python,利用,openpyxl,读取,;如发现本文内容存在版权问题,烦请提供相关信息告之我们,我们将及时沟通与处理。本站内容系统采集于网络,涉及言论、版权与本站无关。



