涉及概念
分断锁
type SimpleCache struct {
mu sync.RWMutex
items map[interface{}]*simpleItem
}
在日常开发中, 上述这种数据结构肯定不少见,因为golang的原生map是非并发安全的,所以为了保证map的并发安全,最简单的方式就是给map加锁。
之前使用过两个本地内存缓存的开源库, gcache, cache2go,其中存储缓存对象的结构都是这样,对于轻量级的缓存库,为了设计简洁(包含清理过期对象等 ) 再加上当需要缓存大量数据时有redis,memcache等明星项目解决。 但是如果抛开这些因素遇到真正数量巨大的数据量时,直接对一个map加锁,当map中的值越来越多,访问map的请求越来越多,大家都竞争这一把锁显得并发访问控制变重。 在go1.9引入sync.Map 之前,比较流行的做法就是使用分段锁,顾名思义就是将锁分段,将锁的粒度变小,将存储的对象分散到各个分片中,每个分片由一把锁控制,这样使得当需要对在A分片上的数据进行读写时不会影响B分片的读写。
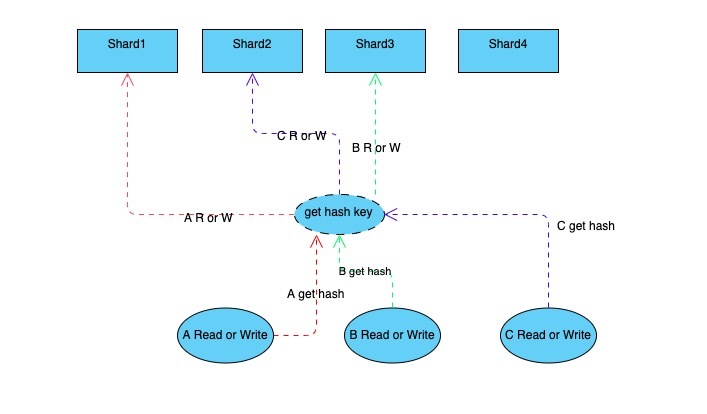
分段锁的实现
// Map 分片
type ConcurrentMap []*ConcurrentMapShared
// 每一个Map 是一个加锁的并发安全Map
type ConcurrentMapShared struct {
items map[string]interface{}
sync.RWMutex // 各个分片Map各自的锁
}
主流的分段锁,即通过hash取模的方式找到当前访问的key处于哪一个分片之上,再对该分片进行加锁之后再读写。分片定位时,常用有BKDR, FNV32等hash算法得到key的hash值。
func New() ConcurrentMap {
// SHARD_COUNT 默认32个分片
m := make(ConcurrentMap, SHARD_COUNT)
for i := 0; i SHARD_COUNT; i++ {
m[i] = ConcurrentMapShared{
items: make(map[string]interface{}),
}
}
return m
}
在初始化好分片后, 对分片上的数据进行读写时就需要用hash取模进行分段定位来确认即将要读写的分片。
获取段定位
func (m ConcurrentMap) GetShard(key string) *ConcurrentMapShared {
return m[uint(fnv32(key))%uint(SHARD_COUNT)]
}
// FNV hash
func fnv32(key string) uint32 {
hash := uint32(2166136261)
const prime32 = uint32(16777619)
for i := 0; i len(key); i++ {
hash *= prime32
hash ^= uint32(key[i])
}
return hash
}
之后对于map的GET SET 就简单顺利成章的完成
Set And Get
func (m ConcurrentMap) Set(key string, value interface{}) {
shard := m.GetShard(key) // 段定位找到分片
shard.Lock() // 分片上锁
shard.items[key] = value // 分片操作
shard.Unlock() // 分片解锁
}
func (m ConcurrentMap) Get(key string) (interface{}, bool) {
shard := m.GetShard(key)
shard.RLock()
val, ok := shard.items[key]
shard.RUnlock()
return val, ok
}
由此一个分段锁Map就实现了, 但是比起普通的Map, 常用到的方法比如获取所有key, 获取所有Val 操作是要比原生Map复杂的,因为要遍历每一个分片的每一个数据, 好在golang的并发特性使得解决这类问题变得非常简单
Keys
// 统计当前分段map中item的个数
func (m ConcurrentMap) Count() int {
count := 0
for i := 0; i SHARD_COUNT; i++ {
shard := m[i]
shard.RLock()
count += len(shard.items)
shard.RUnlock()
}
return count
}
// 获取所有的key
func (m ConcurrentMap) Keys() []string {
count := m.Count()
ch := make(chan string, count)
// 每一个分片启动一个协程 遍历key
go func() {
wg := sync.WaitGroup{}
wg.Add(SHARD_COUNT)
for _, shard := range m {
go func(shard *ConcurrentMapShared) {
defer wg.Done()
shard.RLock()
// 每个分片中的key遍历后都写入统计用的channel
for key := range shard.items {
ch - key
}
shard.RUnlock()
}(shard)
}
wg.Wait()
close(ch)
}()
keys := make([]string, count)
// 统计各个协程并发读取Map分片的key
for k := range ch {
keys = append(keys, k)
}
return keys
}
这里写了一个benchMark来对该分段锁Map和原生的Map加锁方式进行压测, 场景为将一万个不重复的键值对同时以100万次写和100万次读,分别进行5次压测, 如下压测代码
func BenchmarkMapShared(b *testing.B) {
num := 10000
testCase := genNoRepetTestCase(num) // 10000个不重复的键值对
m := New()
for _, v := range testCase {
m.Set(v.Key, v.Val)
}
b.ResetTimer()
for i := 0; i 5; i++ {
b.Run(strconv.Itoa(i), func(b *testing.B) {
b.N = 1000000
wg := sync.WaitGroup{}
wg.Add(b.N * 2)
for i := 0; i b.N; i++ {
e := testCase[rand.Intn(num)]
go func(key string, val interface{}) {
m.Set(key, val)
wg.Done()
}(e.Key, e.Val)
go func(key string) {
_, _ = m.Get(key)
wg.Done()
}(e.Key)
}
wg.Wait()
})
}
}
原生Map加锁压测结果

分段锁压测结果

可以看出在将锁的粒度细化后再面对大量需要控制并发安全的访问时,分段锁Map的耗时比原生Map加锁要快3倍有余
Sync.Map
go1.9之后加入了支持并发安全的Map sync.Map, sync.Map 通过一份只使用原子操作的数据和一份冗余了只读数据的加锁数据实现一定程度上的读写分离,使得大多数读操作和更新操作是原子操作,写入新数据才加锁的方式来提升性能。以下是 sync.Map源码剖析, 结构体中的注释都会在具体实现代码中提示相呼应
type Map struct {
// 保护dirty的锁
mu Mutex
// 只读数据(修改采用原子操作)
read atomic.Value
// 包含只读中所有数据(冗余),写入新数据时也在dirty中操作
dirty map[interface{}]*entry
// 当原子操作访问只读read时找不到数据时会去dirty中寻找,此时misses+1,dirty及作为存储新写入的数据,又冗余了只读结构中的数据,所以当misses > dirty 的长度时, 会将dirty升级为read,同时将老的dirty置nil
misses int
}
// Map struct 中的 read 就是readOnly 的指针
type readOnly struct {
// 基础Map
m map[interface{}]*entry
// 用于表示当前dirty中是否有read中不存在的数据, 在写入数据时, 如果发现dirty中没有新数据且dirty为nil时,会将read中未被删除的数据拷贝一份冗余到dirty中, 过程与Map struct中的 misses相呼应
amended bool
}
// 数据项
type entry struct {
p unsafe.Pointer
}
// 用于标记数据项已被删除(主要保证数据冗余时的并发安全)
// 上述Map结构中说到有一个将read数据拷贝冗余至dirty的过程, 因为删除数据项是将*entry置nil, 为了避免冗余过程中因并发问题导致*entry改变而影响到拷贝后的dirty正确性,所以sync.Map使用expunged来标记entry是否被删除
var expunged = unsafe.Pointer(new(interface{}))
在下面sync.Map具体实现中将会看到很多“双检查”代码,因为通过原子操作获取的值可能在进行其他非原子操作过程中已改变,所以再非原子操作后需要使用之前原子操作获取的值需要再次进行原子操作获取。
compareAndSwap 交换并比较, 用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时导致数据不一致问题。
sync.Map Write
func (m *Map) Store(key, value interface{}) {
// 先不上锁,而是从只读数据中按key读取, 如果已存在以compareAndSwap操作进行覆盖(update)
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok e.tryStore(value) {
return
}
m.mu.Lock()
// 双检查获取read
read, _ = m.read.Load().(readOnly)
// 如果data在read中,更新entry
if e, ok := read.m[key]; ok {
// 如果原子操作读到的数据是被标记删除的, 则视为新数据写入dirty
if e.unexpungeLocked() {
m.dirty[key] = e
}
// 原子操作写新数据
e.storeLocked(value)
} else if e, ok := m.dirty[key]; ok {
// 原子操作写新数据
e.storeLocked(value)
} else {
// 新数据
// 当dirty中没有新数据时,将read中数据冗余到dirty
if !read.amended {
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
func (e *entry) tryStore(i *interface{}) bool {
p := atomic.LoadPointer(e.p)
if p == expunged {
return false
}
for {
if atomic.CompareAndSwapPointer(e.p, p, unsafe.Pointer(i)) {
return true
}
p = atomic.LoadPointer(e.p)
if p == expunged {
return false
}
}
}
// 在dirty中没有比read多出的新数据时触发冗余
func (m *Map) dirtyLocked() {
if m.dirty != nil {
return
}
read, _ := m.read.Load().(readOnly)
m.dirty = make(map[interface{}]*entry, len(read.m))
for k, e := range read.m {
// 检查entry是否被删除, 被删除的数据不冗余
if !e.tryExpungeLocked() {
m.dirty[k] = e
}
}
}
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(e.p)
for p == nil {
// 将被删除(置nil)的数据以cas原子操作标记为expunged(防止因并发情况下其他操作导致冗余进dirty的数据不正确)
if atomic.CompareAndSwapPointer(e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(e.p)
}
return p == expunged
}
sync.Map Read
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 只读数据中没有,并且dirty有比read多的数据,加锁在dirty中找
if !ok read.amended {
m.mu.Lock()
// 双检查, 因为上锁之前的语句是非原子性的
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok read.amended {
// 只读中没有读取到的次数+1
e, ok = m.dirty[key]
// 检查是否达到触发dirty升级read的条件
m.missLocked()
}
m.mu.Unlock()
}
if !ok {
return nil, false
}
// atomic.Load 但被标记为删除的会返回nil
return e.load()
}
func (m *Map) missLocked() {
m.misses++
if m.misses len(m.dirty) {
return
}
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
sync.Map DELETE
func (m *Map) Delete(key interface{}) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 只读中不存在需要到dirty中去删除
if !ok read.amended {
m.mu.Lock()
// 双检查, 因为上锁之前的语句是非原子性的
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok read.amended {
delete(m.dirty, key)
}
m.mu.Unlock()
}
if ok {
e.delete()
}
}
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(e.p)
if p == nil || p == expunged {
return false
}
if atomic.CompareAndSwapPointer(e.p, p, nil) {
return true
}
}
}
同样以刚刚压测原生加锁Map和分段锁的方式来压测sync.Map
压测平均下来sync.Map和分段锁差别不大,但是比起分段锁, sync.Map则将锁的粒度更加的细小到对数据的状态上,使得大多数据可以无锁化操作, 同时比分段锁拥有更好的拓展性,因为分段锁使用前总是要定一个分片数量, 在做扩容或者缩小时很麻烦, 但要达到sync.Map这种性能既好又能动态扩容的程度,代码就相对复杂很多。
还有注意在使用sync.Map时切忌不要将其拷贝, go源码中有对sync.Map注释到” A Map must not be copied after first use.”因为当sync.Map被拷贝之后, Map类型的dirty还是那个map 但是read 和 锁却不是之前的read和锁(都不在一个世界你拿什么保护我), 所以必然导致并发不安全(为了写博我把sync.Map代码复制出来一份把私有成员改成可外部访问的打印指针)


以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。




