最近同事反映,在使用pt-heartbeat监控主从复制延迟的过程中,如果master down掉了,则pt-heartbeat则会连接失败,但会不断重试。
重试本无可厚非,毕竟从使用者的角度来说,希望pt-heartbeat能不断重试,直到重新连接上数据库。但是,他们发现,不断的重试会带来内存的缓慢增长。
重现
环境:
pt-heartbeat v2.2.19,MySQL社区版 v5.6.31,Perl v5.10.1,RHEL 6.7,内存500M
为了避免数据库启停对pt-heartbeat内存使用率的影响,故MySQL和pt-heartbeat分别运行在不同的主机上。
运行pt-heartbeat
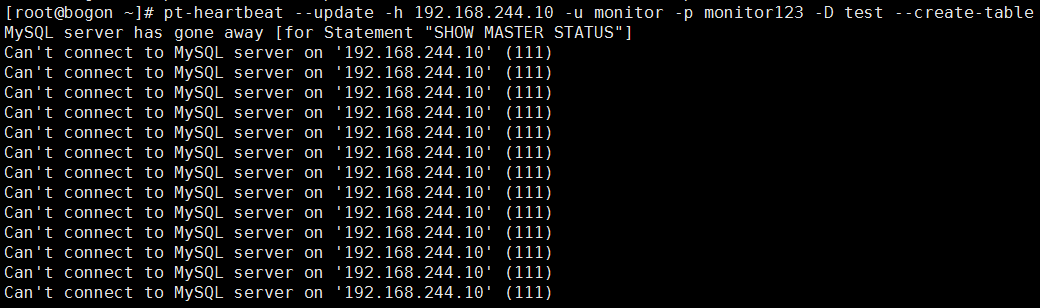
# pt-heartbeat --update -h 192.168.244.10 -u monitor -p monitor123 -D test --create-table
监控pt-heartbeat的内存使用率
获取pid
# ps -ef |grep pt-heartbeat root 1505 1471 0 19:13 pts/0 00:00:08 perl /usr/local/bin/pt-heartbeat --update -h 192.168.244.10 -u monitor -p monitor123 -D test --create-table root 1563 1545 2 19:50 pts/3 00:00:00 grep pt-heartbeat
查看该进程的内存使用率
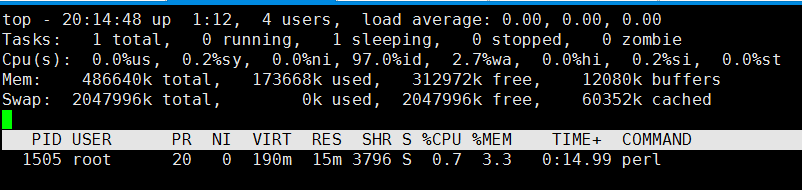
# top -p 1505
运行了0:15.00(TIME+列),MEM一直稳定在3.3%
现关闭数据库
# service mysqld stop
刚才的pt-heartbeat命令不断输出以下信息
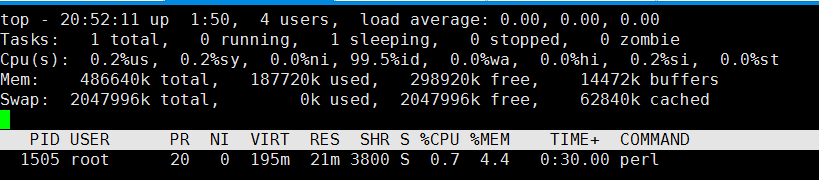
同样CPU时间后,MEM增长到4.4%, 增长了1%,考虑到内存500M,该进程的内存占用增加了5M,虽然不是很多,但考虑到进程的内存增加并没有停止的意思,这个现象还是要引起注意的。
同时,通过pmap命令,发现,0000000001331000地址的RSS和Dirry也会增长,增长的速率是4k/s

后来研究pt-heartbeat的源码,才发现代码有点bug
my $tries = 2;
while ( !$dbh $tries-- ) {
PTDEBUG _d($cxn_string, ' ', $user, ' ', $pass,
join(', ', map { "$_=>$defaults->{$_}" } keys %$defaults ));
$dbh = eval { DBI->connect($cxn_string, $user, $pass, $defaults) };
if ( !$dbh $EVAL_ERROR ) {
if ( $EVAL_ERROR =~ m/locate DBD\/mysql/i ) {
die "Cannot connect to MySQL because the Perl DBD::mysql module is "
. "not installed or not found. Run 'perl -MDBD::mysql' to see "
. "the directories that Perl searches for DBD::mysql. If "
. "DBD::mysql is not installed, try:\n"
. " Debian/Ubuntu apt-get install libdbd-mysql-perl\n"
. " RHEL/CentOS yum install perl-DBD-MySQL\n"
. " OpenSolaris pgk install pkg:/SUNWapu13dbd-mysql\n";
}
elsif ( $EVAL_ERROR =~ m/not a compiled character set|character set utf8/ ) {
PTDEBUG _d('Going to try again without utf8 support');
delete $defaults->{mysql_enable_utf8};
}
if ( !$tries ) {
die $EVAL_ERROR;
}
}
}
以上代码摘自get_dbh函数,用于获取数据库的连接,如果获取失败,则重试1次,然后通过die函数抛异常退出。
但是,通过设置如下断点,发现当$tries为0时,if函数里面的PTDEBUG _d("$EVAL_ERROR")语句能执行,但die函数就是没有抛出异常,并退出脚本
PTDEBUG _d($tries);
if ( !$tries ) {
PTDEBUG _d("$EVAL_ERROR");
die $EVAL_ERROR; }
后来,将上述代码的最后一个if函数修改如下:
if ( !$tries ) {
die "test:$EVAL_ERROR";
}
再次测试
启动数据库
# service mysqld start
执行pt-heartbeat命令
# pt-heartbeat --update -h 192.168.244.10 -u monitor -p monitor123 -D test --create-table
停止数据库
# service mysqld stop
刚才执行的pt-heartbeat命令异常退出

“test:”就是加入的测试字符。
结论
很奇怪,只是单纯的die $EVAL_ERROR不会抛出异常,并退出脚本,但修改后的die "test:$EVAL_ERROR"却会退出脚本。
很显然,这确实是个bug,不知道是不是与perl的版本有关。
很好奇,失败的连接如何导致内存的不断增长?
最后,给percona官方提了个bug
https://bugs.launchpad.net/percona-toolkit/+bug/1629164
以上所述是小编给大家介绍的当master down掉后,pt-heartbeat不断重试会导致内存缓慢增长的原因及解决办法,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!




