在SQL Server中Count(*)或者Count(1)或者Count([列])或许是最常用的聚合函数。很多人其实对这三者之间是区分不清的。本文会阐述这三者的作用,关系以及背后的原理。
往常我经常会看到一些所谓的优化建议不使用Count(* )而是使用Count(1),从而可以提升性能,给出的理由是Count( *)会带来全表扫描。而实际上如何写Count并没有区别。
Count(1)和Count(*)实际上的意思是,评估Count()中的表达式是否为NULL,如果为NULL则不计数,而非NULL则会计数。比如我们看代码1所示,在Count中指定NULL(优化器不允许显式指定NULL,因此需要赋值给变量才能指定)。
复制代码 代码如下:
DECLARE @xx INT
SET @xx=NULL
SELECT COUNT(@xx) FROM [AdventureWorks2012].[Sales].[SalesOrderHeader]
代码清单1.Count中指定NULL
由于所有行都为NULL,则结果全不计数为0,结果如图1所示。
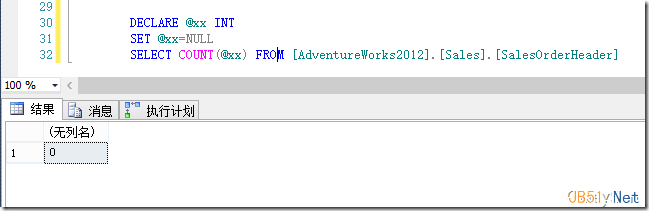
图1.显而易见,结果为0
因此当你指定Count(*) 或者Count(1)或者无论Count(‘anything')时结果都会一样,因为这些值都不为NULL,如图2所示。
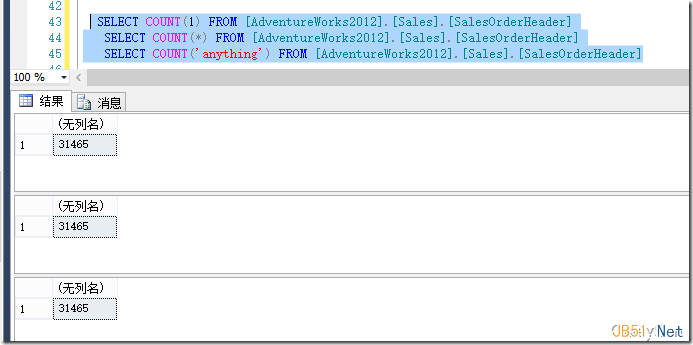
图2.只要在Count中指定非NULL表达式,结果没有任何区别
那Count列呢?
对于Count(列)来说,同样适用于上面规则,评估列中每一行的值是否为NULL,如果为NULL则不计数,不为NULL则计数。因此Count(列)会计算列或这列的组合不为空的计数。
那Count(*)具体如何执行?
前面提到Count( )有不为NULL的值时,在SQL Server中只需要找出具体表中不为NULL的行数即可,也就是所有行(如果一行值全为NULL则该行相当于不存在)。那么最简单的执行办法是找一列NOT NULL的列,如果该列有索引,则使用该索引,当然,为了性能,SQL Server会选择最窄的索引以减少IO。
我们在Adventureworks2012示例数据库的[Person].[Address]表上删除所有的非聚集索引,在ModifyDate这个数据类型为DateTime的列上建立索引,我们看执行计划,如图3所示:

图3.使用了CreateDate的索引
我们继续在StateProvinceID列上建立索引,该列为INT列,占4字节,相比之前8字节 DateTime类型的列更短,因此SQL Server选择了StateProvinceID索引。如图4所示。
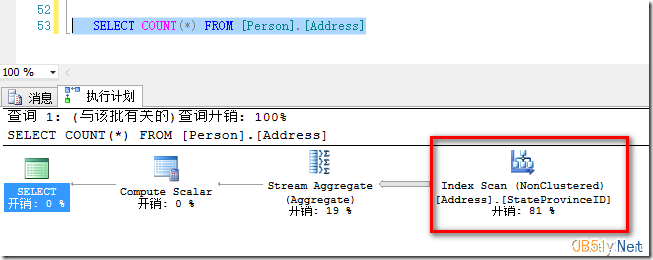
图4.选择了更短的StateProvinceID索引
因此,如果某个表上Count(*)用的比较多时,考虑在一个最短的列建立一个单列索引,会极大的提升性能。
您可能感兴趣的文章:- select count()和select count(1)的区别和执行方式讲解
- MySQL中count(*)、count(1)和count(col)的区别汇总
- sql server中Select count(*)和Count(1)的区别和执行方式
- count(1)、count(*)与count(列名)的执行区别详解
