关于with cube ,with rollup 和 grouping
通过查看sql 2005的帮助文档找到了CUBE 和 ROLLUP 之间的具体区别:
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
再看看对grouping的解释:
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
当看到以上的解释肯定非常的模糊,不知所云和不知道该怎样用,下面通过实例操作来体验一下:
先建表(dbo.PeopleInfo):
复制代码 代码如下:
CREATE TABLE [dbo].[PeopleInfo](
[id] [int] IDENTITY(1,1) NOT NULL,
[name] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[numb] [nchar](10) COLLATE Chinese_PRC_CI_AS NOT NULL,
[phone] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[FenShu] [int] NULL
) ON [PRIMARY]
向表插入数据:
复制代码 代码如下:
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','3223','1365255',80)
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','322123','1',90)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','3213112352','13152',56)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','32132312','13342563',60)
insert into peopleinfo([name],numb,phone,fenshu) values ('王华','3223','1365255',80)
查询出插入的全部数据:
复制代码 代码如下:
select * from dbo.PeopleInfo
结果如图:

操作一:先试试:1, 查询所有数据;2,用group by 查询所有数据;3,用with cube。这三种情况的比较
SQL语句如下:
复制代码 代码如下:
select * from dbo.PeopleInfo --1, 查询所有数据;
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb --2,用group by 查询所有数据;
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --3,用with cube。这三种情况的比较
结果如图:

结果分析:
用第三种(用with cube)为什么会多出来有null的字段值呢?通过分析图上的值得组合会发现是怎么回事儿了,以第三条数据(李欢,null,170)为例:它只是把姓名是【李欢】的分为了一组,而没有考虑【numb】,所以有多出来了第三条数据,也说明了170是怎么来的。其他的也是这样。再回顾一下帮助文档的解释:CUBE 生成的结果集显示了所选列中值的所有组合的聚合, 发现明了了许多。
操作二:1,用with cube;2,用with rollup 这两种情况的比较
SQL语句如下:
复制代码 代码如下:
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --用with cube。
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup --用with rollup。
结果如图:

结果分析:
为什么with cube 比 with rollup多出来一部分呢?原来它没有显示,以【numb】分组而不考虑【name】的数据情况。再回顾一下帮助文档的解释:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合,那这个【某一层次】又是以什么为标准的呢?我的猜想是:距离group up最近的字段必须考虑在分组内。
证明猜想实例:
操作:用两个group up 交换字段位置的sql语句和一个在group up 后面增加一个字段的sql语句进行比较:
SQL语句如下:
复制代码 代码如下:
select [name],numb from dbo.PeopleInfo group by [name],numb with rollup
select [name],numb from dbo.PeopleInfo group by numb,[name] with rollup
select [name],numb,phone from dbo.PeopleInfo group by [name],numb,phone with rollup
结果如图:

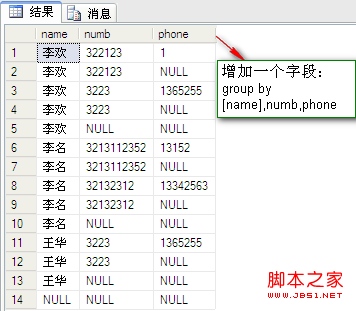
通过结果图的比较发现猜想是正确的。
---------------------------------------------------grouping-------------------------------------------------
现在来看看grouping的实例:
SQL语句看看与with rollup的结合(与with cube的结合是一样的):
复制代码 代码如下:
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
结果如图:

结果分析:
结合帮助文档的解释:当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。 很容易理解再此就不多解释了。
您可能感兴趣的文章:- SQLServer中汇总功能的使用GROUPING,ROLLUP和CUBE
- SQLSERVER中union,cube,rollup,cumpute运算符使用说明
- Sql Server 分组统计并合计总数及WITH ROLLUP应用
- SQLServer 数据库的数据汇总完全解析(WITH ROLLUP)
