关于MySQL的事务隔离级别,相信很多读者都不陌生,网商有很多种相关的文章,很多人对于各种隔离级别,以及不同的级别可以解决的一些读现象都是如数家珍的。
我们知道,ANSI/ISO SQL定义的标准隔离级别有四种,从高到底依次为:可序列化(Serializable)、可重复读(Repeatable Reads)、提交读(Read Committed)、未提交读(Read Uncommitted)。
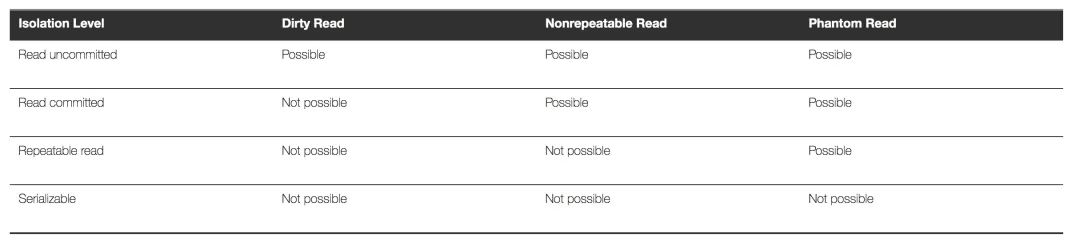
RU隔离级别下,可能发生脏读、幻读、不可重复读等问题。RC隔离级别下,解决了脏读的问题,存在幻读、不可重复读的问题。RR隔离级别下,解决了脏读、不可重复读的问题,存在幻读的问题。Serializable隔离级别下,解决了脏读、幻读、不可重复读的问题。
这四种隔离级别是ANSI/ISO SQL定义的标准定义的,我们比较常用的MySQL对这四种隔离级别是都支持的。但是Oracle数据库只支持Serializable和Read Committed。
但是,可能很多人都不知道,Oracle默认的隔离级别是 RC,而MySQL默认的隔离级别是 RR。
那么,你知道为什么Oracle选择RC作为默认级别,而MySQL要选择RR作为默认的隔离级别吗?
这是我之前面试的时候,问过候选人的一个问题。
很多人认为这个问题没有意义,这不是在逼着我们背八股文么?
但是其实并不是,如果你能耐心的看完这篇文章,你就会发现我的良苦用心。
前面我们说过,Oracle只只支持ANSI/ISO SQL定义的Serializable和Read Committed,其实,根据Oracle官方文档给出的介绍,Oracle支持三种隔离级别:

即Oracle支持Read Committed、Serializable和Read-Only。
Read-Only只读隔离级别类似于可序列化隔离级别,但是只读事务不允许在事务中修改数据,除非用户是SYS。
在Oracle这三种隔离级别中,Serializable和Read-Only显然都是不适合作为默认隔离级别的,那么就只剩Read Committed这个唯一的选择了。
相比于Oracle,MySQL的默认隔离级别的可选范围就比较大了。
首先,我们先从四种隔离级别中排除Serializable和Read Uncommitted这两种,主要是因为这两个级别一个隔离级别太高,一个太低。太高的就会影响并发度,太低的就有脏读现象。
那么,剩下的RR和RC两种,怎么选?
这件事要从long long ago 说起。
在MySQL设计之处,他的定位就是提供一个稳定的关系型数据库。而为了要解决MySQL单点故障带来的问题,MySQL采用主从复制的机制。
所谓主从复制,其实就是通过搭建MySQL集群,整体对外提供服务,集群中的机器分为主服务器(Master)和从服务器(Slave),主服务器提供写服务,从服务器提供读服务。
为了保证主从服务器之间的数据的一致性,就需要进行数据同步,大致的同步过程如下,这里就不详细介绍了

MySQL在主从复制的过程中,数据的同步是通过bin log进行的,简单理解就是主服务器把数据变更记录到bin log中,然后再把bin log同步传输给从服务器,从服务器接收到bin log之后,再把其中的数据恢复到自己的数据库存储中。
那么,binlog里面记录的是什么内容呢?格式是怎样的呢?
MySQL的bin log主要支持三种格式,分别是statement、row以及mixed。MySQL是在5.1.5版本开始支持row的、在5.1.8版本中开始支持mixed。
statement和row最大的区别,当binlog的格式为statemen时,binlog 里面记录的就是 SQL 语句的原文(这句话很重要!!!后面会用的到)。
关于这几种格式的区别,就不在这里详细展开了,之所以要支持row格式,主要是因为statement格式中存在很多问题,最明显的就是可能会导致主从数据库的数据不一致。详细介绍可以参考丁奇在极客时间上面的分享《MySQL实战45讲》。
那么,讲这个主从同步和bin log我们要讲的隔离级别有啥关系呢?
有关系,而且关系很大。
因为MySQL早期只有statement这种bin log格式,这时候,如果使用提交读(Read Committed)、未提交读(Read Uncommitted)这两种隔离级别会出现问题。
比如,在MySQL官网上,有人就给官方曾经提过一个相关的Bug

这个bug的复现过程如下:
有一个数据库表t1,表中有如下两条记录:
CREATE TABLE t1 (
a int(11) DEFAULT NULL,
b int(11) DEFAULT NULL,
KEY a (a)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
insert into t1 values(10,2),(20,1);
接着开始执行两个事务的写操作:

以上两个事务执行之后,数据库里面的记录会变成(11,2)和(20,2),这个发上在主库的数据变更大家都能理解。
因为事务的隔离级别是read committed,所以,事务1在更新时,只会对b=2这行加上行级锁,不会影响到事务2对b=1这行的写操作。
以上两个事务执行之后,会在bin log中记录两条记录,因为事务2先提交,所以UPDATE t1 SET b=2 where b=1;会被优先记录,然后再记录UPDATE t1 SET a=11 where b=2;(再次提醒:statement格式的bin log记录的是SQL语句的原文)
这样bin log同步到备库之后,SQL语句回放时,会先执行UPDATE t1 SET b=2 where b=1;,再执行UPDATE t1 SET a=11 where b=2;。
这时候,数据库中的数据就会变成(11,2)和(11,2)。这就导致主库和备库的数据不一致了!!!
为了避免这样的问题发生。MySQL就把数据库的默认隔离级别设置成了Repetable Read,那么,Repetable Read的隔离级别下是如何解决这样问题的那?
那是因为Repetable Read这种隔离级别,会在更新数据的时候不仅对更新的行加行级锁,还会增加GAP lock。上面的例子,在事务2执行的时候,因为事务1增加了GAP lock,就会导致事务执行被卡住,需要等事务1提交或者回滚后才能继续执行。(关于GAP lock,我后面会有文章单独介绍)。
除了设置默认的隔离级别外,MySQL还禁止在使用statement格式的bin log的情况下,使用READ COMMITTED作为事务隔离级别。
一旦用户主动修改隔离级别,尝试更新时,会报错:
ERROR 1598 (HY000): Binary logging not possible. Message: Transaction level 'READ-COMMITTED' in InnoDB is not safe for binlog mode 'STATEMENT'
所以,现在我们知道了,为什么MySQL选择RR作为默认的数据库隔离级别了吧,其实就是为了兼容历史上的那种statement格式的bin log。
那么,本文讲到这里,算是关于MySQL隔离级别这个知识点讲了大概不到1/5吧,通过这篇文章, 你或许还会有以下问题:
1、row格式和statement有什么区别?使用row的情况下,可以使用RR吗?
2、文中提到的RC的GAP lock到底是什么?
3、RR和RC到底有什么区别?RC是如何解决不可重复读问题的?
4、既然MySQL数据库默认选择了RR,那么,为啥像阿里这种大的互联网公司会把默认的隔离级别改成RC?
关于以上几个问题,你知道答案吗,或者你对哪个更感兴趣呢?欢迎留言!我会挑大家较为感兴趣的专题在后面的文章中继续深入展开介绍。
现在你还觉得这个问题没有意义吗?
我其实是想通过这样一个看似无意义的问题,延展出更多的知识,这样可以更加全方位的了解候选人。
到此这篇关于为什么MySQL选择Repeatable Read作为默认隔离级别的文章就介绍到这了,更多相关MySQL Repeatable Read默认隔离级别内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!




