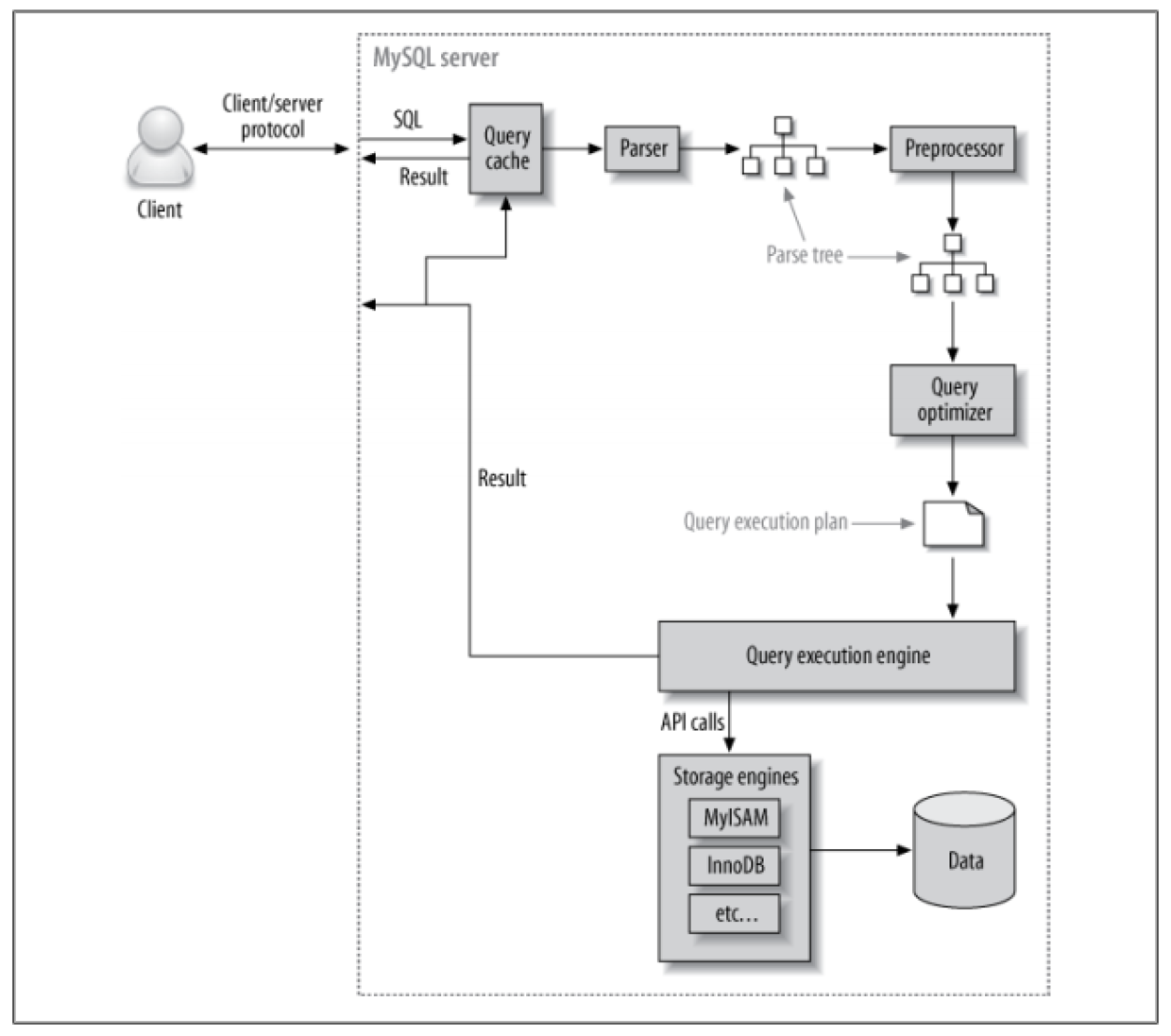
如果需要从 MySQL 服务端获得很高的性能,最佳的方式就是花时间研究 MySQL 优化和执行查询的机制。一旦理解了这些,大部分的查询优化是有据可循的,从而使得整个查询优化的过程更有逻辑性。下图展示了 MySQL 执行查询的过程:
上述的几个步骤都有其复杂性,接下来几篇文章将详细讲述各个环节。查询优化过程尤其复杂,并且理解这一环节很重要。
虽然并不需要了解 MySQL 客户端/服务端协议的内部细节,但需要从高应用层面理解其是如何工作的。这个协议是半双工的,这意味着 MySQL 服务端不同同时发送和接收消息,以及不可以将消息拆成多条短消息发送。这种机制一方面使得 MySQL 的通信简单快速,另一方面也增加了一些限制。例如,这意味着无法进行流控,一旦一方发送了消息,另一方在响应前必须接收整个消息。这就好像来回打乒乓球一样,同一时间只有一方有球,只有接到了球才能把它打回去。
客户端通过单个数据包将查询语句发送给服务端,因此在存在大的查询语句时配置 max_allowed_packet 很重要。一旦客户端发送查询语句后,它就只能等待返回结果。
相反,服务端的响应通常是由多个数据包组成的。一旦服务端响应后,客户端必须获取整个结果集。客户端没法简单地获取几行然后告诉服务端不要再发送剩余的数据。如果客户端仅仅需要返回数据前面的几行,只能是等待服务端全部数据返回后再从中丢弃不需要的数据,或者是粗暴地断开连接。不管哪种方式都不是好的选择,因此合适的 LIMIT子句就显得十分重要。
大部分的 MySQL连接库支持获取整个结果集并在内存中缓存起来,或者是获取需要的数据行。默认的行为通常是获取整个结果集然后在内存缓存。知道这一点很重要,因为 MySQL 服务端在所有请求的数据行没返回前,不会释放这次查询的锁和资源。大部分客户端库会让你感觉数据是从服务端获取的,实际上这些数据可能仅仅是从缓存中读取的。这在大部分时间是没问题的,但对于耗时很久或占据很多内存的大数据量查询来说就不合适了。如果指定了不缓存查询结果,那么占用的内存会更小,并且可以更快地处理结果。缺点是这种方式会在查询时引起 服务端的锁和资源占用。
以 PHP 为例,以下是PHP常用的查询代码:
?php
$link = mysql_connect('localhost', 'user', 'password');
$result = mysql_query('SELECT * FROM huge_table', $link);
while ($row = mysql_fetch_array($result)) {
//处理数据结果
}
?>
这个代码看起来好像是只获取了需要的数据行。然而,这个查询通过 mysql_query 的调用后实际上将全部结果放到了内存中。而 while 循环实际上是对内存中的数据进行循环迭代。相反,如果使用 mysql_unbuffered_query 替代 mysql_query 的话,那就不会缓存结果。
?php
$link = mysql_connect('localhost', 'user', 'password');
$result = mysql_unbuffered_query('SELECT * FROM huge_table', $link);
while ($row = mysql_fetch_array($result)) {
//处理数据结果
}
?>
不同的编程语言处理缓存覆盖的方式不同。例如,Perl 的 DBD::mysql 驱动需要通过 mysql_use_result 属性指定 C 语音客户端库(默认是 mysql_buffer_result),示例如下:
#!/usr/bin/perl
use DBI;
my $dbn = DBI->connect('DBI:mysql:;host=localhost', 'user', 'password');
my $sth = $dbn->prepare('SELECT * FROM huge_table', {mysql_use_result => 1});
$sth->execute();
while (my $row = $sth->fetchrow_array()) {
#处理数据结果
}
注意到 prepare 指定了使用结果而不是缓存结果。也可以通过在连接的时候指定,这会使得每次查询都不缓存。
my $dbn = DBI->connect('DBI:mysql:;mysql_use_result=1;host=localhost', 'user', 'password');
以上就是解读MySQL的客户端和服务端协议的详细内容,更多关于MySQL 客户端和服务端协议的资料请关注脚本之家其它相关文章!




