前言
众所周知, 在多线程中,因为共享全局变量,会导致资源修改结果不一致,所以需要加锁来解决这个问题,保证同一时间只有一个线程对资源进行操作
但是在分布式架构中,我们的服务可能会有n个实例,但线程锁只对同一个实例有效,就需要用到分布式锁----redis setnx
原理
修改某个资源时, 在redis中设置一个key,value根据实际情况自行决定如何表示
我们既然要通过检查key是否存在(存在表示有线程在修改资源,资源上锁,其他线程不可同时操作,若key不存在,表示资源未被线程占用,允许线程抢占,然后将通过setnx设置vlaue,表示资源上锁,其他线程不可同时操作)
图示:
分析
我们的服务处于一个集群中,如果只是简单的的使用线程锁来解决以上问题,是存在问题的:因为线程是基于进程的,两个web server处于不同的进程空间
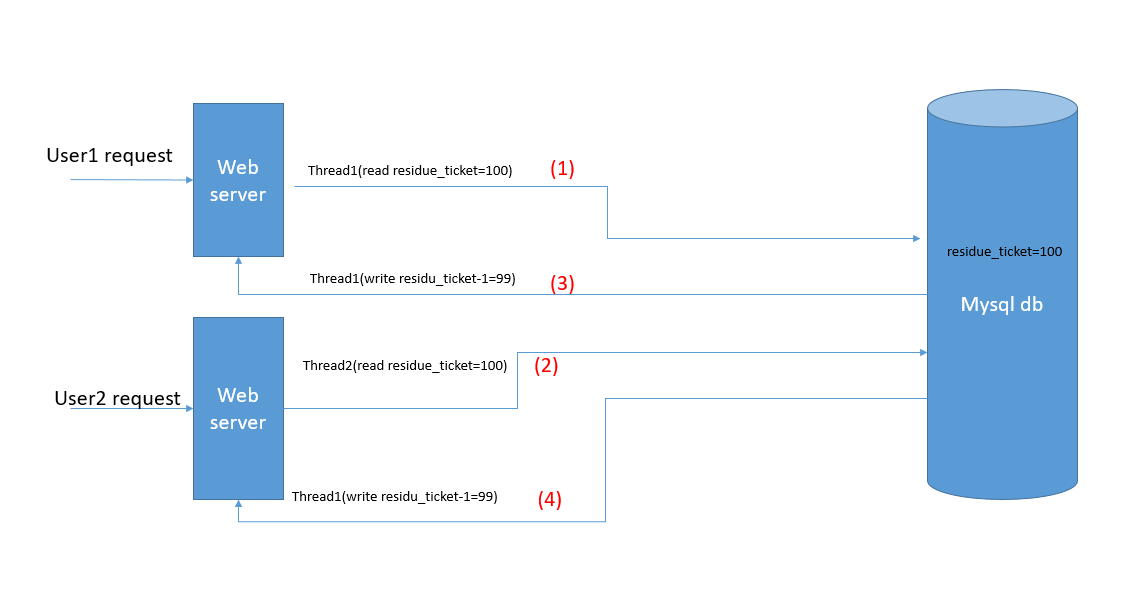
也就是说,user1的请求发往web server1,那只能与web server1的其他请求进行锁的操作,而不能对web server2的请求产生影响
上面的图中,user1发往web server1的请求负责处理的线程为Thread1,同理负责处理user2发往web server2的请求的线程thread2
在同一时刻1,两个线程都读取了mysql中residue_ticket的值为100,对应上图 (1)(2), 各自对100进行-1操作,更新到数据库,对应(3)(4)
我们预期的情况是residue_ticket值被减少了两次,应该为98,但是实际情况下,两个线程都做了100-1=99的操作,并都将mysql中的值改为了99, 的这就会导致最终数据不一致,所以就要用到分布式锁。
为什么用redis?
因为redis是单线程的,不存在多线程资源竞争,并且它真的很快
为什么用setnx 而不是set?
setnx表示只有在key不存在时才能设置成功,但是set会在key存在的情况下修改value
利用setnx的特性,我们可以这样这样设计:
伪代码:
# 设置redis锁的
redis key = 'residue_ticket_lock'
# get_ticket是处理购票的逻辑
def get_ticket():
time_out = 5 # 为了防止线程过多,当前线程获取不到锁,长时间处于循环中而导致的性能影响,我们设置一个超时时间,如果当前线程在超时时间内还没有抢占到分布式锁,就返回失败的结果
while True:
if redis.setnx('residue_ticket_lock','lock',5):
# 如果setnx返回True, 表示此刻没有其他线程在操作数据库,当前线程可以上锁成功,注意不仅设置了value=lock,还设置了过期时间,这是必要的,为了防止上锁的线程异常崩掉导致不能释放(删除key)而导致其他所有线程永远拿不到操作权
residue_ticket = mysql.get('residue_ticket') # 从mysql中获取当前剩余票数
mysql.update('residue_ticket',residue_ticket-1) # 订购成功,将票数-1,更新数据到mysql
# 删除key,释放锁
redis.del('residue_ticket')
return True
else:
# 如果setnx返回False,表示有其他线程对在操作,当前线程等待0.01s,并继续循环
time.sleep(0.01)
time_out -= 0.01
continue
return False
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
您可能感兴趣的文章:- redis单线程快的原因和原理
- 解决Spring session(redis存储方式)监听导致创建大量redisMessageListenerContailner-X线程问题
- Redis不是一直号称单线程效率也很高吗,为什么又采用多线程了?

