OpenStack是当前最主流、最热门的云平台,携程OpenStack环境除了应用在携程网站,还广泛应用于携程呼叫中心的桌面云系统。作为业界最领先的呼叫中心之一,携程服务联络中心几万员工365x24小时提供全球化服务,让说走就走的亲们毫无后顾之忧。
桌面云极大地提升了IT运维效率,显着降低了用户故障率,是未来IT的一大发展趋势。那么携程是如何把这两者高效结合部署于携程呼叫中心的?
本文将主要分享携程呼叫中心广泛使用的桌面云系统,介绍这套基于OpenStack的云桌面系统架构以及在开发过程中碰到的一些OpenStack相关问题,并分享云桌面系统运维、监控、自动化测试等。
一、为什么要使用虚拟云桌面
1、背景
携程呼叫中心,即服务联络中心,是携程的核心部门之一,现有几万员工。他们全年7x24小时为全球携程用户提供服务。以前呼叫中心桌面使用台式PC,随着业务规模扩大,PC维护量倍增,需要投入大量人力、物力、财力来报障系统稳定运行。为此,携程正式引入虚拟云桌面。
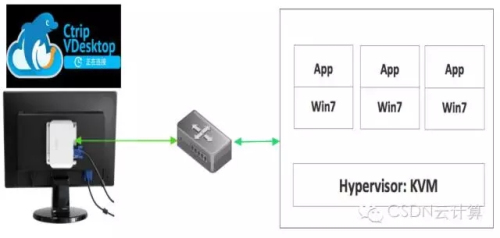
虚拟云桌面是什么?如图所示,用户桌面PC机换成了一个云桌面瘦客户端(ThinClient,TC)。所有的CPU、内存、硬盘都在云端。云端跑满虚拟机,用户桌面通过瘦客户端连入虚拟机使用Windows。其中,虚拟机采用QEMU加KVM实现,云环境用OpenStack进行管理,远程桌面协议是第三方高度定制、修改过的spice协议。
2、云桌面的优势
第一,运维成本。PC部署以及系统软件安装耗时较长,云桌面后台5分钟一台自动交付可供用户使用的虚拟机;PC扩大部署投入巨大,云桌面只需要购买少量服务器接入云系统,快速扩大部署。
第二,故障处理效率。PC有问题,有可能需技术人员到用户现场开箱检查,故障排查耗时较长,严重点的硬件问题如需更换配件,等待周期更长。云桌面故障标准是5分钟处理完毕。对于5分钟无法解决的问题,只需后台更换虚拟机解决。
第三,运维管理。PC分散在用户桌面,运维需要用户配合(比如保持开机)。云桌面提供了运维系统,只需设定好时间、安装任务参数,系统会全自动进行安装维护。同时,瘦客户端轻量,无任何用户数据,对用户也带来极大便利。典型的如用户位置迁移,云桌面无需搬移,只需用户到新位置登录即可。
最后,云桌面整体低碳、环保。瘦客户端功率跟普通节能灯相近,比PC低一个数量级。
3、携程云桌面现状
携程云桌面现已部署上海、南通、如皋、合肥、信阳、穆棱六个呼叫中心。几百台计算节点、近万坐席,而且规模还在不断扩大中,新的呼叫中心也在计划中。
同时,云桌面平台故障率、瘦客户端故障率也远低于PC故障率。下图是携程运维部门的故障率统计图。
二、如何实现虚拟云桌面
1、云桌面原架构
携程云桌面后台云平台在实践中进行了多次迭代,原有架构如上图所示。该架构特点是,直接在OpenStack Nova进行定制开发,添加了分配虚拟的接口,实现瘦客户端直接访问OpenStack获取虚拟机信息。
这个架构下,云桌面平台可以直接访问全部的虚拟机信息,直接进行全部的虚拟机操作,数据也集中存在OpenStack数据库,部署方便。用户权限通过OpenStack Keystone直接管控,管理界面使用OpenStack Horizon并添加云桌面管理页面。
典型的分配虚拟机用例中,瘦客户端通过OpenStack Keystone进行认证、获取Token,然后访问Nova请求虚拟机。如上图所示,瘦客户端会通过Keystone进行认证,Keystone确认用户存在后向域LDAP进行密码校验,确认用户合法后返回Token;瘦客户端再通过Token向Nova申请虚拟机。
Nova根据瘦客户端设置的坐席信息,首先查找这个坐席是否已分配虚拟机。如有直接返回对应虚拟机。如无,从后台空闲虚拟机中进行分配并更新数据库分配,返回远程桌面协议连接信息。
2、原架构局限性
随着业务增长,原架构出现一些局限性,首先,业务与OpenStack呈强绑定关系,导致OpenStack升级涉及业务重写;修改业务逻辑需要对整个云平台做回归测试。
其次,用户必须要是Keystone用户,用户管理必须使用Keystone模型。导致Keystone与LDAP之间要定期同步进行,有时还需手工同步特殊用户。
管理层面,因为Horizon的面向云资源管理的,但业务主要面向运维的。这部分差异,导致我们开发新的Portal来弥补,管理人员需要通过两套系统来进行运维。
整体方案上,云桌面远程桌面协议由第三方提供,如果第三方方案不支持OpenStack,就无法在携程云桌面系统使用。
最后,用户部门有各种需求,直接在OpenStack内进行开发难度大,上线时间长,开发人员很难实现技术引领业务发展。
3、新架构
经过架构调整,新架构实现了OpenStack与我们的业务解耦,同时适应用户部门的业务发展方向,方便功能快速迭代上线。
从图中可以看出,云桌面业务逻辑从OpenStack中独立出来,成为了VMPool,Allocator;管理层独立开发一套面向IT运维的Portal系统,取代Horizon;云平台可直接原生的OpenStack。
其中VMPool负责维护某种规格虚拟机的可用数量,避免需要的时候没有虚拟机可用,让用户等待。Allocator满足符合条件的用户请求,返回用户对应的虚拟机或者从VMPool分配虚拟机分配用户。
对于用户分配虚拟机的典型用例,与原有架构改动较大。首先,业务层瘦客户端将直接访问业务层的API。API层会直接通过LDAP进行用户认证,并获取用户OU、组别等信息。
接着,业务层将进行用户规则匹配。每个Allocator通过用户组、OU、tag等进行规则匹配,以确定该用户是否由自己进行服务。如不满足Allocator所定义的规则,将按Allocator的优先等级,继续选取下一个Allocator进行匹配,直到匹配或者默认规则为止。
匹配后,如果是有绑定关系的分配规则,比如用户绑定或者坐席绑定、TC绑定,那Allocator将直接从数据库返回已有的绑定;如果无绑定关系,Allocator就会从对应的VMPool分配一台虚拟给,返回给用户。
最后,对用户部门来说,看到的是用户属于一个组,这个组对应特定的虚拟机。只需调整用户属性,即可实现用户分配特定的虚拟机,充分满足他们的各种需求。
三、大规模部署中遇到各种坎
1、软件版本选取
在搭建OpenStack前,必须进行需求分析,确定所需的需求。然后根据需求选取满足条件的OpenStack及相关组件的版本,以避免后期出现各种系统及虚拟机问题。
我们根据携程呼叫中心的业务需要,选好了几个版本的KVM、QEMU,以及OpenVSwitch,在选取能适配它们的几个可用kernel、Libvirt版本,并剔除了不稳定版本或者有已知问题的版本,将这些组件组成合理的组合,进行7x24小时用户模拟自动测试,找到最稳定、合适的并满足需求的,作生产上线使用。
2、资源超分
超分与应用场景强关联。一定要首先确定需求,是CPU密集、内存密集、IO密集还是存储密集。在做了充足的用户调查后,我们准备了大量用户模拟自动化脚本,进行自动化测试,以选取最合理超分值。
从我们的测试结果看,瓶颈主要是内存。内存超分过度会导致主机直接OOM(Out Of Memory)宕机。Windows及Windows应用吃内存比较严重,特别是像Chrome这些程序,优先占用内存先。虽然我们使用KSM(Kernel Samepage Merging,相同内存页合并功能),省了一些内存,但最终上线也只能达到1:1.2的超分。
对于IO,在Windows启动阶段比较明显。大量Windows同时启动时会造成启动风暴情,在我们的极端条件测试中出现过启动Windows需要40分钟,硬盘IO100%使用,每个读写请求平均0.2秒响应。所以,在大规模部署时,对虚拟机并发开机数一定要有一定限制。同时,硬盘一定要多块做RAID,以提供更高的IO吞吐量。
最后是CPU。CPU过度超分会严重影响用户体验。但是一般不会造成宿主机宕机。在我们的测试条件下,超分到1:2用户体验开始下降,所以实际上线超分不多。
最终我们现在生产环境,是以内存为标准进行超分,硬盘、CPU控制在可接受范围。
3、网络细节
多DNSMasq实例问题
我们虚拟机的IP地址通过DHCP获取。DHCP服务端我们使用的DNSMasq比较老,只是简单的实现了多实例运行,但并未真正实现绑定到虚拟接口。
在生产环境,我们观察到VM都能获取IP,但是在续租IP的时候大量失败。经抓包分析,虚拟机在第一次请求IP时,由于自身无IP地址,使用的是广播方式进行DHCP请求;在续租时,由于本身有IP地址,也已明确DHCP服务端地址,所以采用IP点对点单播请求。
服务端,多个DNSMasq实例运行的情况下,如果是广播包,所有DNSMasq都收到消息,所有广播请求能正确回复。在单播情况下,只有最后启动的DNSMasq能收到请求,最终导致虚拟机得不到正确的DHCP续租响应。最终我们通过升级DNSMasq解决。
宿主机重启导致虚拟机网络不通
在物理机重启后,有时会出现VM网络不通。经过调查,我们分析出根本原因是libvirt,ovs的启动、关闭顺序。
在正常情况下,libvrit退出时会删除它管理的OpenVSwitch Port以及它创建的对应的Tap虚拟网卡。libvirt启动时会创建需要的Tap网卡,并请求OpenVSwitch创建对应的Port建立虚拟连接。
逻辑上,OpenVSwitch Port相当于交换机网口。Tap网卡,相当于PC的网卡。他们之间需要连线网络才能正常通信。
如果关机时,OpenVSwitch比Libvirt先停止,Libvirt将不能成功删除它管理的OpenVSwitch Port;开机时,如果OpenVSwitch先启动,它将建试图重建之前存在的port。但因为Libvirt还未启动,OpenVSwitch Port对应的Tap网卡还未创建(即虚拟网口对应的虚拟网卡不存在),OpenVSwitch重建Port最终失败并且Port将被销毁。
由于Port信息对OpenVSwitch来说是用户配置信息,OpenVSwitch并不会从数据库中清理掉对应的Port记录。所以等到Libvirt启动调用OpenVSwitch创建Port时,OpenVSwitch发现数据库里面已经存在这些Port,所以并未真正触发Port重建,最后造成VM网络不通。
最终我们通过开、关机顺序调整实现问题修复。
RabbitMQ长连接
RabbitMQ是OpenStack使用的一种消息交交互组件。OpenStack在某些时候,会出现无法创建虚拟机的情况。通过日志分析我们发现计算节点没有收到对应的创建请求消息。然后抓包分析进一步发现,TCP数据包被防火墙拦截、丢弃。原来防火墙对TCP会话有数量限制,会定期丢弃长久无数据交互的TCP会话。
在了解根本原因后,一方面通过定期自动冒烟测试保证网络不空闲,一方面想解决方案。从应用层面上,我们调研到RabbitMQ已经有心跳机制,但要升级。由于升级影响范围太广,最终没有进行。
接着我们对网络层面进行了调查,发现TCP本身有Keepalive保活机制,同时RabbitMQ代码本身也有TCP保活,但默认不开启。最后我们通过启用RabbitMQTCP保活机制,设置一个合理的保活间隔解决问题。
四、系统稳定背后的黑科技
1、运维工具
运维是云桌面的一大难题,为此我们专门设计了运维系统,通过两套SaltStack系统实现了对瘦客户端与虚拟机的管理;通过Portal系统实现对整个系统的管理。
具体功能上,运维上,实现了对虚拟机、宿主机的可视化监控、管理,并能对虚拟机实现远程管理;对IT管理人员,实现了自动化的软件安装、文件下发、密码修改、数据找回,、发送通知等功能;对资产管理员,实现了TC状态监控,TC异常情况及时发现。还有其它大量工作仍在开发进行中。
2、监控告警
监控方面,除了常规的服务器、操作系统层面的监控,我们实现了大量业务层监控。比如通过监控已经连接云桌面的瘦客户端用户输入事件,实现实时活跃用户监控,使得我们能实时监控系统负载、用户数量。通过对比部门排班,第一时间发现用户数异常。
同时,对OpenStack的各种告警、ERROR的也添加了监控,确保云平台的稳定。对虚拟机网络、CPU等也进行了相应监控,确保虚拟机对于用户的高可用性。
3、自动化测试
通过在瘦客户端实现用户输入输出模拟,我们实现了全自动的测试环境。我们搭建了专门的云桌面测试实验室,数十台盒子进行7x24小时自动测试,全力验证系统各项变更,支持业务各种研究探索,保障系统稳定性。
同时,通过传统的CI框架,我们搭建了代码的单元测试、集成测试环境,已经大量的线上测试用例,不仅有力的保障了软件质量,还能定期对线上系统进行体检,第一时间发现系统异常。